使用正则快速从 js 文件里提取处 API path 渗透测试
前言
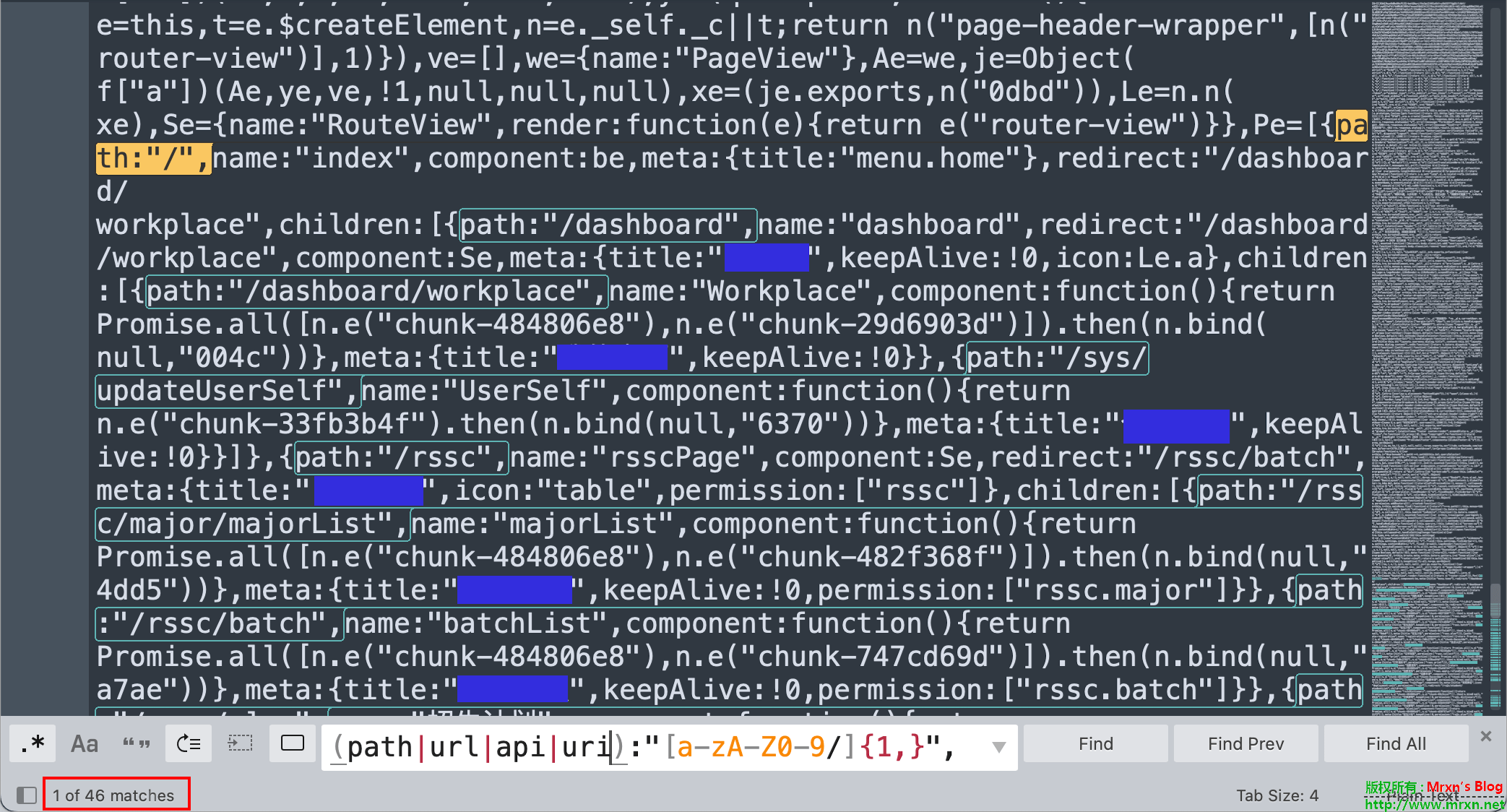
在渗透测试的时候,遇到前后分离的站点,多数与后端通信的 API path 就在 js 文件里,且大多数名称为 app.xxxx.js 这类以 app 开头的 js 文件里面。
而且这类 js 文件大多数是混淆过的,或者压缩过,又臭又长!
正则提取 API path
在 js 文...
解决burpsuite拦截Firefox或chrome的一些无用报文数据 技术文章
前言:
在我们使用 burpsuite 进行渗透测试或其他抓包APP测试的时候,经常会在 burpsuite 里面出现大量的无用报文数据,比如使用 Firefox 配合 burpsuite 抓包时经常出现:
http://detectportal.firefox.com/success.txt ,重点是这个包 Forward 和 Drop还会点不动!
这些大量的报文严重影响我们的工作效率!我就我的经验分享给大家,同时做个笔记。
要解决上面这个问题很简单,可以在 Firefox 浏览器里关闭或者是我后面说的直接在 burpsuite 里面使用正则过滤,先说一下如何在浏览器里关闭这个报文:
在地址栏输入: about:config 回车进入,---> 我了解此风险 ---> 搜索 : network.captive-portal-service.enabled ---> 双击将 值改为false,OK,就关掉了。
但是,在我们测试的时候有时候出现大量的无关的子域名或者是暂时先屏蔽某个子域名的信息,不让它显示在 burpsuite 的 target 里面
小计一个正则匹配提取实例之从网页中提取所有域内链接 技术文章
比如某个网站包含如下的内容:
<select name="select7" class="textbox" style="width: 200px;" onchange="MM_jumpMenu('parent',this,0)">
<option selected="selected">---------〖校内机构〗---------</option>
<option>————管理机构————</option>
<option value="/dzbgs/">党政办公室</option>
<option value="/xcb/">党委组织宣传部</option>
<option value="/rsc/">人事处</option>
<option value="/jwc/">教务处</option>
<option value="/xsc/">学生处(党委学工部)</option>
<option value="/zsxx/">招生办公室</option>
<option value="/jyb/">就业指导办公室</option>
<option value="/cwc/">财务处</option>
<option value="/zcc/">资产管理处</option>
<option value="/wsc/">国际合作交流处</option>
<option value="/kyc/">科研处</option>
<option value="/dds/">督导室</option>
<option value="/zlpg/">质量监控与评估中心</option>
<option value="/bwc/">保卫处(武装部、安全稳定办公室)</option>
<option value="/hq/">后勤服务公司</option>
<option>————教学机构————</option>
<option value="/yyyyxy/">英语语院</option>
<option value="/dfyyyxy/">东方语学院</option>
<option value="/yayyxy/">西方语学院</option>
<option value="/gjsxy/">国际商学院</option>
<option value="/gjwhjlxy/">文学与新闻传播学院</option>
<option value="/gsgl/">管理学院</option>
<option value="/ysxy/">艺术学院</option>
<option value="/yyxy/">音乐学院</option>
<option value="/szjyb/">思想政治理论教研部</option>
<option value="/tyb/">体育部</option>
<option value="/jxjyxy/">继续教育学院</option>
<option>————教辅机构————</option>
<option value="/tsg/">图书馆</option>
<option value="/net/">现代教育技术中心</option>
<option>————教辅机构————</option>
<option value="/gh/">工会</option>
<option value="/tw/">团委</option>
</select>
我们要提取你面的所有的内域的网址,就是value后面的值:"/tw/",手工不说,最为原始的方法,体力活我们要尽量少干,正则走起啊!
使用正则提取两个双引号之间的内容,正则表达式很简单:
/(.*)[A-Z-a-z]/

这样我们提取出来了,可是没有加上域名啊,如何是好?答案就是继续正则啊,骚男不要犹豫,对于网页内内容,没有正则提取不了的(先吹个牛逼-_-|hh ):
(.?^/)

直接批量替换每行的第一个斜杠为域名不就OK了,上图域名结尾少了个斜杠.别跳坑里了!效果如下,就好了,前前后不到一分钟搞定,收工,比我写这篇文章还快!
本来不想写的,这么久了没发文章,手痒痒,凑个数!仅当笔记.
http://www.xxxx.com/dzbgs/ http://www.xxxx.com/xcb/ http://www.xxxx.com/rsc/ http://www.xxxx.com/jwc/ http://www.xxxx.com/xsc/ http://www.xxxx.com/zsxx/ http://www.xxxx.com/jyb/ http://www.xxxx.com/cwc/ http://www.xxxx.com/zcc/ http://www.xxxx.com/wsc/ http://www.xxxx.com/kyc/ http://www.xxxx.com/dds/ http://www.xxxx.com/zlpg/ http://www.xxxx.com/bwc/ http://www.xxxx.com/hq/ http://www.xxxx.com/yyyyxy/ http://www.xxxx.com/dfyyyxy/ http://www.xxxx.com/yayyxy/ http://www.xxxx.com/gjsxy/ http://www.xxxx.com/gjwhjlxy/ http://www.xxxx.com/gsgl/ http://www.xxxx.com/ysxy/ http://www.xxxx.com/yyxy/ http://www.xxxx.com/szjyb/ http://www.xxxx.com/tyb/ http://www.xxxx.com/jxjyxy/ http://www.xxxx.com/tsg/ http://www.xxxx.com/net/ http://www.xxxx.com/gh/ http://www.xxxx.com/tw/
好了,牛逼吹完了,洗洗睡了.我们下回见,对于不懂得正则可以评论,我可以帮你试试哦!
PS: 牛逼的娃娃们不要乱搞,这是我测试项目的.谢谢!
-
admin 约 23 小时前
@東咩:无
-
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
哥,还能再分享不 百度账号:東咩
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。
-
admin 2024-03-28 22:38
@人大代表:卧槽 别搞我...
-
24年的新闻,你22年爆出来了。厉害了,大哥。

