windows10安装kali子系统&&https: aptMethod::Configuration: could not load seccomp policy: Invalid argument解决办法 Linux
windwos10安装kali Linux子系统,后更新系统若是出现如下错误:
https: aptMethod::Configuration: could not load seccomp policy: Invalid argument
一般是你的源有问题,可以尝试修改你的源,我就是通过修改源治好了这个毛病!(注:以下命令都是在root权限下执行得,你可以通过sudo su 来切换到root权限下)
nano /etc/apt/sources.list
修改成如下(仅供参考,可以自己测试可用的速度快的,反正国内得总是出错-_-|):
#deb http://http.kali.org/kali kali-rolling maindeb http://ftp.ne.jp/Linux/packages/kali/kali kali-rolling main
然后执行一下命令更新即可:
apt-get update && apt-get dist-upgrade && apt-get install wget -y
然后可以安装apt install apt-transport-https,然后尝试使用官方源(deb https://http.kali.org/kali kali-rolling main)更新。
执行完上面的步骤后,你可以通过执行 wget 命令,如果返回类似下面得信息,则表示你的wget安装好了!
root@mrxn:/# wgetwget: missing URLUsage: wget [OPTION]... [URL]...
Try `wget --help' for more options.
我这边可以跑到560KB/s左右,如果觉得慢,可以开VPN/代理加速。
出现意思错误是因为我想wget一个东西的时候,提示我命令未找到,然后就安装wget,失败,到切换源,成功安装wget,成功wget我需需要下载得东西,然后呢。。。就有了这篇日经贴!
大致简记一下如何再windows10上安装kali Linux子系统:
参照官方文档:https://docs.microsoft.com/en-us/windows/wsl/install-win10
win+Q 搜索powershell,然后以管理员的方式 打开,执行如下命令:
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
官方文档说,执行命令后,根据提示执行重启。但是我的提示是RESTARTNEEED:FALSE 。
so,我不需要重启!@_@||记不太清,有可能我之前开启了Linux子系统,wangle !。。。
插一句:开启Linux子系统,在 控制面板—程序和功能—启用或关闭Windows功能—把Linux子系统复选框勾上即可


接下来就是去应用商店搜索kali 即可找打,然后安装吧!一百多兆,很快的。接下来就是上面得解决错误。。。
接下来就是安装xfce4,
wget https://raw.githubusercontent.com/Mr-xn/server-bash-script/master/xfce-xrdp.sh
sh xfce-xrdp.sh
差不多三十几分钟左右就好了(渣渣本,配置好点会更快)。



然后用命令 service xrdp start 来启动xrdp,在本地使用远程桌面连接127.0.0.1:3390 即可打开GUI界面了。


用户名和密码就是安装kali时设置的账号密码。

进去后选择 Use default config 加载默认配置即可。

然后进入桌面:很简洁

使用 uname -a 可以看到是老版本得kali 并不是最新版得。

当不需要的时候,可以使用 service xrdp stop 停止XRDP进程即可

总结:windows下得Linux子系统,可以用,但是不是很好用。但是对硬件要求比较高,显卡或者内存不高或导致运行很慢。。。当然了,这个年代,SSD必备!
参考文章链接:
https://github.com/meefik/linuxdeploy/issues/869
系统中X1-lock进程Xorg占用CPU爆表通过shell脚本解决以及shell一些知识【笔记】 Linux
首先看一下这张CPU的近一周的波动统计图,可以知道从2月28日开始一路飙升,并且后来时不时的自动停止,这个起伏真的是 因吹丝挺啊!(小声嘀咕:QNMLGB!

我那两天忙,没时间看,这几天空了上去一看傻眼了。。。CPU爆表啊,.X1-lock占用CPU98% ,在Top命令下 C查看进程一看是Xorg,我擦,难道中马了(一种不祥的预感,事实是的-_-|| >悲伤<):

![]()
我就想起了前段时间折腾nextcloud,装了各种插件,而其中ocdownloader需要aria2c,我就去Google搜索啊,结果我也忘了借鉴了谁的,估计装到了个假的aria2c,于是乎就中马了。。。

好吧,删除了aria2c以及nextcloud,终止那个wget 进程 并删掉残留//瞬间清静了。。。但是,我后来发现了,这个木马其实占用的CPU并不高(并不一定 =_= 无奈自己太菜不知道如何确定 )<< 从上图得出的结果。
后来Google搜索啊,询问了大佬以及网友的记录,大致如下:
Xorg这个进程多半是是由 vncserver 产生的,所以由此可以推定因为 VNC 服务导致了 CPU 占用超高。连接 VNC 需要请求 GUI 资源,如果机器配置和网络条件不够好,那么资源占用高是必然的了。如果无法升级硬件配置,那么可以考虑调整 VNC 设置,将所需的 GUI 要求降低,如减少分辨率、颜色位深等。
但是我在自己的服务器上找了半天,都没有找到神马vncserver,于是乎,只能自己先写个脚本监控它(因为这个进程的名字不变,如果进程的名字会改变,稍微修改一下我的脚本也可以使用的),如果一出现就直接FUCK kill它。脚本结果运行截图如下:

注:脚本可以写进crontab 定时执行,监控,暂时就这么个暴力解决的办法。脚本地址:https://github.com/Mr-xn/server-bash-script/blob/master/freecpu.sh
后来找了好久,终于找到方法了。。。卸载所有X11相关的包以及Xorg的包,然后查找系统里面的X11相关路径文件和文件夹,全部删除掉。。。OK了!几个小时都没有再出现 .X1-lock 被杀的记录了。卸载相关参考命令我会给出链接,至于查找嘛,很简单,whereis X11 ,apt-get --purge remove 'x11-*'
root@xxxx:~# whereis X11
X11: /usr/bin/X11 /usr/lib/X11 /etc/X11 /usr/include/X11 /usr/share/X11root@xxxx:~# rm -rf /usr/bin/X11 /usr/lib/X11 /etc/X11 /usr/include/X11 /usr/share/X11
终止掉 .X1-lock 进程在进行这些删除操作就好了。
root@xxxx:~# find / -name 'xorg'
/usr/share/X11/xkb/rules/xorg
root@xxxx:~# ls -lgth /usr/share/X11/xkb/rules/xorg
lrwxrwxrwx 1 root 4 Jun 6 2014 /usr/share/X11/xkb/rules/xorg -> base
至于这个xorg 的内容我贴在这里了,你们有看的,可以去查看:https://pastebin.com/WCxn3Bux
删完后 你继续查找 如果像下面这个就表示删干净了。
root@xxxx:~# whereis xorg
xorg:
root@xxxx:~# whereis X11
X11:
root@xxxx:~#
相关参考链接:
https://www.howtoinstall.co/en/debian/jessie/x11-common?action=remove
https://www.wikihow.com/Configure-X11-in-Linux
https://raspberrypi.stackexchange.com/questions/5258/how-can-i-remove-the-gui-from-raspbian-debian (这个里面比较详细)
下面是写shell 的一些笔记,生人勿看。
linux shell中 if else以及大于、小于、等于逻辑表达式介绍:
比如比较字符串、判断文件是否存在及是否可读等,通常用"[]"来表示条件测试。
注意:这里的空格很重要。要确保方括号的空格。我就曾因为空格缺少或位置不对,而浪费好多宝贵的时间。
if ....; then
....
elif ....; then
....
else
....
fi
[ -f "somefile" ] :判断是否是一个文件
[ -x "/bin/ls" ] :判断/bin/ls是否存在并有可执行权限
[ -n "$var" ] :判断$var变量是否有值
[ "$a" = "$b" ] :判断$a和$b是否相等
-r file 用户可读为真
-w file 用户可写为真
-x file 用户可执行为真
-f file 文件为正规文件为真
-d file 文件为目录为真
-c file 文件为字符特殊文件为真
-b file 文件为块特殊文件为真
-s file 文件大小非0时为真
-t file 当文件描述符(默认为1)指定的设备为终端时为真
含条件选择的shell脚本 对于不含变量的任务简单shell脚本一般能胜任。但在执行一些决策任务时,就需要包含if/then的条件判断了。shell脚本编程支持此类运算,包括比较运算、判断文件是否存在等。
基本的if条件命令选项有:
eq —比较两个参数是否相等(例如,if [ 2 –eq 5 ])
-ne —比较两个参数是否不相等
-lt —参数1是否小于参数2
-le —参数1是否小于等于参数2
-gt —参数1是否大于参数2
-ge —参数1是否大于等于参数2
-f — 检查某文件是否存在(例如,if [ -f "filename" ])
-d — 检查目录是否存在
几乎所有的判断都可以用这些比较运算符实现。脚本中常用-f命令选项在执行某一文件之前检查它是否存在。
shell 的 if 条件判断中有多个条件:
-------------------------------------------------------#!/bin/bashscore=$1if [ $score = 5 ]||[ $score = 3 ];then else fi-------------------------------------------------------#!/bin/bashscore=$1if [ $score -gt 5 ]||[ $score -lt 3 ];then else fi-------------------------------------------------------#!/bin/bashscore=$1if [ $score -gt 15 ]||([ $score -lt 8 ]&&[ $score -ne 5 ]);then else fi-------------------------------------------------------或:#!/bin/bash
count="$1"
if [ $count -gt 15 -o $count -lt 5 ];then
fi
且:#!/bin/bash
count="$1"
if [ $count -gt 5 -a $count -lt 15 ];then
fi-------------------------------------------------------
score=$1
if [[ $score -gt 15 || $score -lt 8 && $score -ne 5 ]];then
else
fi记住必须加两个中括号!!!
linux shell脚本 截取字符串时执行错误:bad substitution :
#/bin/bash
mm="www.baidu.com"
echo ${mm:0:3} 方式1、sh cutstr.sh
结果:Bad substitution
方式2、bash cutstr.sh
结果:www
方式3、
chmod 777 cutstr.sh./cutstr.sh结果:www
结论:
在执行脚本时要注意的是执行环境的shell,Ubuntu 中执行最好使用上面的方式二或者方式三,注意使用方式一时有时会报错。
<span style="color:#FF0000;"><strong>#!/bin/sh</strong></span> test=asdfghjkl echo ${test:1} Kali一键安装docker脚本 Linux
Kali不介绍,docker简单的介绍一下:如何通俗解释docker是什么 我的理解用一句话来说就是:在你的系统里面装一个盒子,盒子里你可以干任何事!另外,在gitbook上也有专门的专题介绍,想详细的了解的可以去看一下:
https://yeasy.gitbooks.io/docker_practice/content/
本文主要介绍在Kali下如何一键安装,给懒人看的-_- .
Kali是属于Debian的一个分支基于Debian Wheezy 因此安装方法借助docker官方的Debian安装文档,但是官方的安装方法在Kali上会失败...
所以呢,我就自己Google啊,找到了好几个版本,我结合自己的实际操作和理解,搞了一个综合性的脚本.
下面就是脚本的全部代码:
#!/bin/bash
#=================================================
# Description: Install docker for Kali
# Version: 0.0.1
# Author: Mrxn
# Blog: https://mrxn.net/Linux/install_docker_script_for_Kali.html
# PS: 欢迎大家到github提建议和bug
#=================================================
# install dependencies
sudo apt-get install apt-transport-https ca-certificates curl gnupg software-properties-common dirmngr# use https get sources
sudo echo "deb https://http.kali.org/kali kali-rolling main non-free contrib" > /etc/apt/sources.list
sudo echo "deb-src https://http.kali.org/kali kali-rolling main non-free contrib" >> /etc/apt/sources.list
# update apt-get
export DEBIAN_FRONTEND="noninteractive"
sudo apt-get update# remove previously installed Docker
sudo apt-get purge lxc-docker*
sudo apt-get purge docker.io*
# add Docker repo gpg key
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -# add deb docker sources
sudo echo "deb [arch=amd64] https://download.docker.com/linux/debian stretch stable" >> /etc/apt/sources.listcat > /etc/apt/sources.list.d/docker.list <<'EOF'
deb https://apt.dockerproject.org/repo debian-stretch main
EOF
sudo apt-get update# install Docker
sudo apt-get install docker-ce# run Hellow World image
sudo docker run hello-world# manage Docker as a non-root user
sudo groupadd docker
sudo usermod -aG docker $USER# configure Docker to start on boot
sudo systemctl enable docker
有啥bug 就去github提吧... https://github.com/Mr-xn/Kali-install-docker
linux下解压rar格式的文件 Linux
linux下一般都是tar和zip的,如果下载到的文件是rar格式的话.我们就需要另外安装rar解压缩软件来支持了.下面简记一下
首先从rarlab官网的下载页面找到你所对应的版本.32位或者是64位的linux版本.
https://www.rarlab.com/download.htm
我这里以64位的作为例子.
在命令行里面使用wget直接下载:
wget https://www.rarlab.com/rar/rarlinux-x64-5.5.0.tar.gz
然后解压:
tar zxvf rarlinux* 或者是准确的使用Tab键补全. tar zxvf rarlinux-x64-5.5.0.tar.gz
然后cd进入rar目录进行编译安装
cd rar
make
make install
root@kali:~# cd rar
root@kali:~/rar# make
mkdir -p /usr/local/bin
mkdir -p /usr/local/lib
cp rar unrar /usr/local/bin
cp rarfiles.lst /etc
cp default.sfx /usr/local/lib
root@kali:~/rar# make install
mkdir -p /usr/local/bin
mkdir -p /usr/local/lib
cp rar unrar /usr/local/bin
cp rarfiles.lst /etc
cp default.sfx /usr/local/lib
这时候使用rar 命令会提示你它的使用方法.常见使用方法如下:
解压缩一个file.rar 命令: rar x file.rar
压缩一个文件: rar a file2.rar ./test (将当前目录下的test文件夹压缩为file2.rar)
其他具体命令请使用rar查看.
PS:上篇文章的命令行下载工具里,axel 对于允许同时多线程下载的特别有用,wget 更适合下载只允许单线程的...
Linux 下十大命令行下载工具(转) Linux
我们一想到Linux,肯定会想到黑白终端,真正的Linux用户总是偏爱从终端来进行工作,哪怕是用于下载。相比某种GUI工具,命令行下载工具可以帮助用户更迅速地从网上下载任何东西。有许多可满足一般用途、甚至用于torrent的下载工具,不过相比其它工具,只有像curl或者wget这少数几款工具更受欢迎。我们在本教程中将探讨用于在Linux环境中下载的十大命令行工具。不妨逐一探讨这些CLI工具。
1.Wget
这是最有名的工具,可用于通过CLI下载。这款工具功能很丰富,可以充当某种功能完备的GUI下载管理器,它拥有一款理想的下载管理器所需要的所有功能,比如它可以恢复下载,可以下载多个文件,出现某个连接问题后,可以重新尝试下载,你甚至可以管理最大的下载带宽。
例子
从网上下载某个示例文件:
# wget http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
示例输出:
--2016-05-11 16:56:23-- http://www.sample-
videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
Resolving www.sample-videos.com (www.sample-videos.com)...
166.62.28.98
Connecting to www.sample-videos.com (www.sample-
videos.com)|166.62.28.98|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1055736 (1.0M)
Saving to: ‘big_buck_bunny_720p_1mb.mp4’
100%[==========================================================================================================>] 10,55,736 52.1KB/s in 24s
2016-05-11 16:56:47 (43.4 KB/s) - ‘big_buck_bunny_720p_1mb.mp4’ saved [1055736/1055736]
后台下载文件:
# wget -b http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
如果互联网连接出现中断,恢复下载。
# wget -c http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
从某个密码保护的ftp软件库下载文件。
# wget --ftp-user=<user_name> --ftp-password=<Give_password> Download-url-address
2.Curl
Curl是另一种高效的下载工具,它可以用来上传或下载文件,只要使用一个简单的命令。它支持暂停和恢复下载程序包,并支持数量最多的Web协议,可预测下载完成还剩余多少时间,可通过进度条来显示下载进度。它是所有Linux发行版的内置工具。这是一款快速高效的工具,不妨看一下。
例子:
# curl -o um.mp4 http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
示例输出:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1030k 100 1030k 0 0 105k 0 0:00:09 0:00:09 --:--:-- 111k
借助-o选项,提供名称,下载文件会以该名称保存;如使用-O选项,文件就会以原始名称保存。
# curl -O http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
使用一个curl命令,下载多个文件。
# curl -O http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_2mb.mp4 -O
3.Axel
这是wget的出色替代者,是一款轻量级下载实用工具。它实际上是个加速器,因为它打开了多路http连接,可下载独立文件片段,因而文件下载起来更快速。
安装
# apt-get install axel
例子
# axel http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
Initializing download: http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
示例输出:
File size: 1055736 bytes
Opening output file big_buck_bunny_720p_1mb.mp4.0
Starting download
[ 0%] .......... .......... .......... .......... .......... [ 64.9KB/s]
[ 4%] .......... .......... .......... .......... .......... [ 83.0KB/s]
[ 9%] .......... .......... .......... .......... .......... [ 91.5KB/s]
[ 14%] .......... .......... .......... .......... .......... [ 96.8KB/s]
[ 19%] .......... .......... .......... .......... .......... [ 100.2KB/s]
[ 24%] .......... .......... .......... .......... .......... [ 102.7KB/s]
[ 29%] .......... .......... .......... .......... .......... [ 104.6KB/s]
[ 33%] .......... .......... .......... .......... .......... [ 86.9KB/s]
[ 38%] .......... .......... .......... .......... .......... [ 77.1KB/s]
[ 43%] .......... .......... .......... .......... .......... [ 64.8KB/s]
[ 48%] .......... .......... .......... .......... .......... [ 66.8KB/s]
[ 53%] .......... .......... .......... .......... .......... [ 72.8KB/s]
[ 58%] .......... .......... .......... .....
Connection 1 finished
,,,,,,,,,, ,,,,,,,,,, ,,,,,,,,,, ,,,,,..... .......... [ 74.1KB/s]
[ 63%] .......... .......... .......... .......... .......... [ 79.8KB/s]
[ 67%] .......... .......... .......... .......... .......... [ 84.5KB/s]
[ 72%] .......... .......... .....
Connection 2 finished
,,,,,,,,, ,,,,,,,,,, ,,,,,..... .......... .......... [ 86.3KB/s]
[ 77%] .......... .......... .......... .......... .......... [ 91.6KB/s]
[ 82%] .......... .......... .......... .......... .......... [ 96.7KB/s]
[ 87%] .......... .......... .......... .......... .......... [ 101.6KB/s]
[ 92%] .......... .......... .......... ...
Connection 0 finished
,,,,,,,,,, ,,,,,,,,,, ,,,,,,,,,, ,,,....... .......... [ 105.9KB/s]
[ 96%] .......... .......... ..........
Downloaded 1031.0 kilobytes in 9 seconds. (108.66 KB/s)
4.Youtube-dl
这是一款专用工具,可以通过命令行从YouTube下载视频,这是个易于安装的程序包,可用来下载一大批文件。
安装
# curl https://yt-dl.org/latest/youtube-dl -o /usr/local/bin/youtube-dl
变更文件权限:
# sudo chmod a+rx /usr/local/bin/youtube-dl
例子
下载一些视频,只要为命令添加视频URL参数。
# youtube-dl https://www.youtube.com/watch?v=UZW2hs-2OAI
想下载视频列表,将所有URL拷贝到一个文本文件中,然后运行下面这个命令:
-
# youtube-dl -a <name_of_your_text_file.txt>
示例输出:
virtual-System-Product-Name prozilla-2.0.4-master # youtube-dl -a url.txt[youtube] xEf8A7X53YE: Downloading webpage[youtube] xEf8A7X53YE: Downloading video info webpage[youtube] xEf8A7X53YE: Extracting video information[youtube] xEf8A7X53YE: Downloading MPD manifest[download] Destination: EIC Outrage - Salute to Indian Athletes!-xEf8A7X53YE.mp4[download] 3.9% of 70.87MiB at 82.53KiB/s ETA 14:04
5.Aria2
这是一种开源命令行下载加速器,支持多个端口,你可以使用最大带宽来下载文件,是一款易于安装、易于使用的工具。
安装
# apt-get install aria2### 针对centOS# yum install aria2
例子
# aria2c http://www.sample-videos.com/video/mp4/720/big_buck_bunny_720p_1mb.mp4
示例输出:
[#28c7dd 0.9MiB/1.0MiB(93%) CN:1 DL:70KiB ETA:1s]05/11 23:06:47 [NOTICE] Download complete:/home/virtual/Desktop/prozilla-2.0.4-master/big_buck_bunny_720p_1mb.mp4Download Results:gid |stat|avg speed |path/URI======+====+===========+=======================================================28c7dd|OK | 72KiB/s|/home/virtual/Desktop/prozilla-2.0.4-master/big_buck_bunny_720p_1mb.mp4Status Legend:(OK):download completed.
6.Movgrab
这是用于下载视频的另一款高效工具,使用movgrab的优点在于,它不仅可以从YouTube下载视频,还可以从几乎所有的知名网站下载视频,比如metacafe、dailiymotion、 ehow和vobx等。这是一款很快速的工具,可以定义影片格式,还可以恢复下载。
安装
可以从该链接下载程序包。
解压缩程序包:
# tar -xvf movgrab-1.2.1.tar.gz# cd movgrab-1.2.1# ./configure# make# make install
使用命令下载程序包
下载名称指定的文件:
# movgrab Youtube_url
指定输出文件:
# movgrab -o example.mp4 video_url
使用maovgrab –h,即可了解更多的细节。
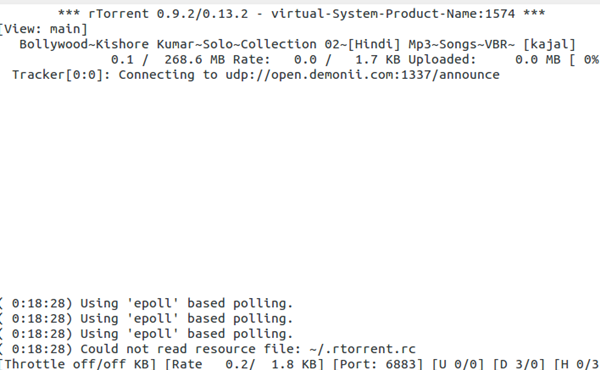
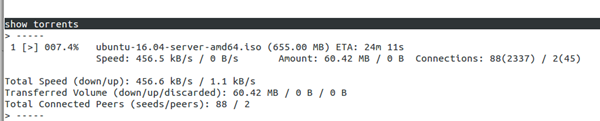
7.rtorrent
这种知名的命令行torrent客户软件随附在所有Linux发行版中,它需要screen实用工具才能正常运行。
安装
安装screen:
# apt-get install screen
安装rtorrent :
# apt-get install rtorrent
例子
# rtorrent example.torrent
8.ctorrent
C-torrent是最简单的命令行torrent下载工具,可以迅速安装,也是micro-torrent或utorrent的优秀替代者。
安装
# apt-get install ctorrent
例子
我们不妨下载一份最新版本的Ubuntu server 16.04。
# ctorrent ubuntu-16.04-server-amd64.iso.torrent
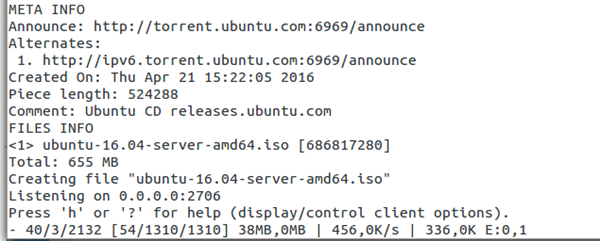
使用ctorrent –h,即可了解更多选项。
9.Transmission-cli
Transmission的这个命令行版本是一款非常强大的工具,可用于下载torrent。易于安装,它需要screen这个依赖项。
安装
# apt-get install transmission-cli transmission-daemon transmission-common
安装screen
# apt-get install screen
例子
# screen -a /usr/bin/transmission-cli -p 25000 ubuntu-16.04-server-amd64.iso.torrent
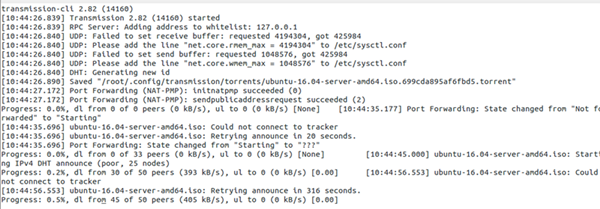
10.vuze
这是一种全面的torrent下载解决方案,占用资源极少,是功能最强大的torrent应用程序之一,它需要Java才能在控制台上运行,所以确保你已将open jdk的jre安装到系统上,它同样需要screen程序包。
安装
可以直接从该链接下载,下载后解压缩程序包。
# tar -xvf VuzeInstaller.tar.bz2# cd vuze
有一些依赖项必须下载,从该链接获取必要的插件。
将这些.jar插件拷贝到vuze目录:
# cp *.jar vuze
运行下面这个命令:
# java -cp "Azureus2.jar:commons-cli.jar:log4j.jar" org.gudy.azureus2.ui.common.Main --ui=console
上述命令成功执行后,运行下面这个命令来启动
# screen java -jar Azureus2.jar --ui=console
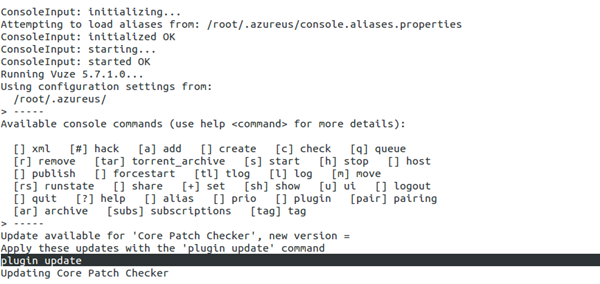
使用help命令,给add命令添加上.torrent文件的路径,即可开始下载。
结束语
相比基于GUI的torrent或下载管理器,命令行工具来得更高效而快速。这些工具在无外设服务器中扮演重要角色,可以控制慢速互联网连接中的带宽使用。
请尽情享用!
原文链接:http://www.unixmen.com/top-10-command-line-tools-downloading-linux/
linux使用问题处理小计(勿入) Linux
在ubuntu10.10下没有dig命令,而debian6下面有这个命令
ubuntu下想要apt-get安装,发现没有找到dig软件包
搜索后才发现正确安装是安装dnsutils
apt-get install dnsutils
PS:redhat系列这样安装
yum install bind-utils
看看dig命令大多时候如何可以取代nslookup的:
www@www:~# dig www.google.com
; <<>> DiG 9.9.5-9+deb8u14-Debian <<>> www.google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19569
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;www.google.com. IN A;; ANSWER SECTION:
www.google.com. 164 IN A 216.58.194.196;; Query time: 1 msec
;; SERVER: 108.61.10.10#53(108.61.10.10)
;; WHEN: Thu Oct 05 17:21:52 CST 2017
;; MSG SIZE rcvd: 59
只输出mx记录,简明使用
dig mx www.google.com +short
只输出NS记录
dig ns www.google.com
查询SOA( Start of Autority ) 返回主DNS服务器
dig soa www.google.com
指定dns,例如查询8.8.8.8中的www.google.com记录
dig +short @8.8.8.8 www.google.com
大部分的时候dig最下面显示了查询所用的时间及DNS服务器,时间,数据大小。DNS超时时间为30秒,查询时间对于排查DNS问题很有用。
;; Query time: 1 msec
;; SERVER: 108.61.10.10#53(108.61.10.10)
;; WHEN: Thu Oct 05 17:21:52 CST 2017
;; MSG SIZE rcvd: 59
nginx提示Failed to read PID from file /run/nginx.pid:
在centos7上,配置nginx代理服务后:
systemctl status nginx.service
提示错误:
Failed to read PID from file /run/nginx.pid: Invalid argument
看到好多说删掉改nginx.pid 文件的,试之,无效。
后来找到了一个方法:
mkdir -p /etc/systemd/system/nginx.service.d
printf "[Service]\nExecStartPost=/bin/sleep 0.1\n" > /etc/systemd/system/nginx.service.d/override.conf
然后:
systemctl daemon-reload
systemctl restart nginx.service
解决了问题。
为nginx添加这些额外的第三方扩展加速你的web吧 Linux

Nginx 是一款高性能 Web 服务器软件,其有非常有益的IO表现,而且相较于 Apache Httpd 配置更加简单上手更加容易,本文将向大家介绍编译安装 Nginx 的第三方扩展。
Nginx 的额外扩展:
- OpenSSL 1.1.0,提供 ALPN 支持,支持 HTTP/2
- Nginx-CT,透明证书提高 HTTPS 网站的安全性和浏览器支持
- ngx_PageSpeed,Google 家的网站性能优化工具
- Brotli,实现比 Gzip 更高的压缩率
- Jemalloc,优化内存管理
第一个openssl和最后一个jemalloc现在大多数的一件安装包都有包括,不做描述.需要的请自行Google搜索相关教程.今天主要说一下Nginx-CT,ngx_PageSpeed,Brotli这三个扩展的安装.(建议把第三方扩展都放在一个文件夹下面方便管理)
下载需要的源码包:
wget https://github.com/grahamedgecombe/nginx-ct/archive/v1.3.2.tar.gz
tar xzf v1.3.2.tar.gz
git clone https://github.com/google/ngx_brotli.git
cd ngx_brotli
git submodule update --initwget https://github.com/pagespeed/ngx_pagespeed/archive/v1.12.34.3-stable.zip
unzip v1.12.34.3-stable.zip
cd ngx_pagespeed-1.12.34.3-stable/
wget https://dl.google.com/dl/page-speed/psol/1.12.34.2-x64.tar.gz
tar -xzvf 1.12.34.2-x64.tar.gz
接下来就是编译了,这是在已经安装好nginx的环境增加扩展,所有只需要make 不需要make install ,不然就覆盖安装了...
linux下错误提示很人性化的,多看提示,更具提示操作,基本上都可以解决问题.
重要步骤:
通过命令 nginx -V 查看nginx的配置及其已有的扩展.我们只需要在后面增加模块即可:
比如使用nginx -V命令查看结果类似于下面:
--prefix=/usr/local/nginx --with-http_stub_status_module
我们只需要在原有的基础上添加我们的模块即可:
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --add-module=/data/software/nginx-ct-1.3.2 --add-module=/data/software/ngx_brotli --add-module=/data/software/ngx_pagespeed-1.12.34.3-stable
等它自动配置完成后,直接 make 一下就行.
然后备份原有已安装好的nginx:
cp /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.bak
service nginx stop
然后将刚刚编译好的nginx覆盖掉原有的nginx(这个时候nginx要停止状态,通过上面的命令,已经停止了):
cp ./objs/nginx /usr/local/nginx/sbin/
然后启动nginx (service nginx start),就可以通过命令nginx -V 查看第三方扩展是否已经加入成功.
PS:笔记+分享,好的扩展,开源产品大家都应该去体验一下!
两种方式反代Google(镜像)--nginx反代和nginx扩展 Linux
写这篇文章的缘由是看见了我的博友Secret他写了一篇文章:
造轮子之谷歌镜像站 让我想起了 之前自己折腾过的nginx扩展镜像Google,效率比这个高,而且支持高级的配置,多级配合组成类似集群的功能,今天又折腾了一下,所以写一下过程,以方便后来需要的人.
声明:请在法律允许范围内合理使用搜索引擎,本文只作为技术笔记,不负任何责任.
- 更新库
- apt-get update
- # 安装 gcc & git
- apt-get install build-essential git gcc g++ make -y
- # nginx 官网: http://nginx.org/en/download.html
- wget "http://nginx.org/download/nginx-1.8.1.tar.gz"
- # pcre 官网:http://www.pcre.org/
- wget "ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.39.tar.gz"
- # opessl 官网:https://www.openssl.org/
- wget "https://www.openssl.org/source/openssl-1.0.1t.tar.gz"
- # zlib 官网:http://www.zlib.net/
- wget "http://zlib.net/zlib-1.2.8.tar.gz"
- # 下载本扩展
- git clone https://github.com/cuber/ngx_http_google_filter_module
- # 下载 substitutions 扩展
- git clone https://github.com/yaoweibin/ngx_http_substitutions_filter_module
- # 解压缩
- tar xzvf nginx-1.8.1.tar.gz && tar xzvf pcre-8.39.tar.gz && tar xzvf openssl-1.0.1t.tar.gz && tar xzvf zlib-1.2.8.tar.gz
- # 进入 nginx 源码目录
- cd nginx-1.8.1
- # 创建 nginx 安装目录
- mkdir /usr/local/nginx-1.8.1
编译nginx及其扩展
- # 设置编译选项
- ./configure \
- --prefix=/usr/local/nginx-1.8.1 \
- --with-pcre=../pcre-8.39 \
- --with-openssl=../openssl-1.0.1t \
- --with-zlib=../zlib-1.2.8 \
- --with-http_ssl_module \
- --add-module=../ngx_http_google_filter_module \
- --add-module=../ngx_http_substitutions_filter_module
- # 编译, 安装
- # 如果扩展有报错, 请发 issue 到
- # https://github.com/cuber/ngx_http_google_filter_module/issues
- make
- make install
最后启动nginx,访问你的服务器IP或者是解析到上面的域名,即可看到nginx是否安装好.
ngx_http_google_filter_module项目github地址(他那里也有说明,不过是英文的,能看懂的可以直接去看原文):
https://github.com/cuber/ngx_http_google_filter_module
下面说一下nginx的配置:
- 简单的单机配置https,已经不支持http反代了
- server {
- server_name <你的域名>;
- listen 443;
- ssl on;
- ssl_certificate <你的证书>;
- ssl_certificate_key <你的私钥>;
- resolver 8.8.8.8;
- location / {
- google on;
- }
- }
- 进阶配置:配置多个服务器来缓解并发和出现验证码的频率
google_scholar 依赖于 google, 所以 google_scholar 无法独立使用. 由于谷歌学术近日升级, 强制使用 https 协议, 并且 ncr 已经支持, 所以不再需要指定谷歌学术的 tld
- location / {
- google on;
- google_scholar on;
- # 设置成德文,默认的语言是中文简体
- google_language "de";
- }
Upstreaming
upstream 减少一次域名解析的开销, 并且通过配置多个网段的 google ip 能够一定程度上减少被 google 机器人识别程序侦测到的几率 (弹验证码). upstream 参数要放在 http{} 中(也就是放在server{}配置外),注意这个参数只有你加了SSL证书是https的时候才会有效,否则会报错! 寻找这个参数的谷歌IP很简单,在你的VPS上面 ping www.google.com ,获得的IP把最后一位数 加1或者减1 就行了。
upstream www.google.com { server 173.194.38.1:443; server 173.194.38.2:443; server 173.194.38.3:443; server 173.194.38.4:443; }
Proxy Protocol--代理保护
默认情况下,代理将使用https与后端服务器通信。您可以使用google_ssl_off强制某些域名回退到http协议。如果要通过没有ssl证书的另一个网关来代理某些域,这是非常有用的。
# # eg. # i want to proxy the domain 'www.google.com' like this # vps(hk) -> vps(us) -> google # # # configuration of vps(hk) # server { # ... location / { google on; google_ssl_off "www.google.com"; } # ... } upstream www.google.com { server < ip of vps(us) >:80; } # # configuration of vps(us) # server { listen 80; server_name www.google.com; # ... location / { proxy_pass https://www.google.com; } # ... }所有的这些配置都是在全新的机器上配置,如果你已经配置好了nginx那么,也很容易,你只需要重新添加扩展动态编译进去就好了,编译完切记不要make install,只需要make编译,然后覆盖就行.
./configure \
--prefix=/usr/local/nginx \
--user=www \
--group=www \
--with-http_stub_status_module \
--with-http_v2_module \
--with-http_ssl_module \
--with-http_gzip_static_module \
.......
--add-module=/data/software/ngx_http_google_filter_module \
--add-module=/data/software/ngx_http_substitutions_filter_module
注意:你需要在nginx的源码包文件夹下面执行这个./configure命令,使用之前先使用 nginx-V 查看nginx版本下载相同版本的源码包,添加扩展的时候要注意路径,在最好复制的时候先停止nginx,同时以防万一,先拷贝一份nginx在覆盖.参考资料如下:
http://imshusheng.com/linux/173.html
http://www.ttlsa.com/nginx/how-to-install-nginx-third-modules/
就到这里了.下次再见:) 最后 欢迎访问我的Google镜像:gg.mrxn.net
利用grep,cut,awk处理一些文本的简记 Linux
先来案例一波:
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。 Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
假设我们有一段需要处理的文本内容如下所示(数量几万行,手工别说了,先使用替换命令将|替换成空格):
[email protected]:cory0212 [email protected]:morris409 [email protected]:marigold [email protected]:jeffrey2 [email protected]:123q123q | [email protected]:dinosaur52197 | [email protected]:goblue20 | [email protected]:Recon1234 | [email protected]:32gunz32 | Premium [email protected]:happily1 | [email protected]:susana123 | [email protected]:silvia231106 | Standard [email protected]:hockey30 | [email protected]:KtnM990175 | Basic [email protected]:arturs2000 |
我们需要从上面这段文本里面提取分离出邮箱和冒号后面竖线|之间的这两部分.如何操作呢?
首先 提取邮箱,我们可以使用grep来配合正则表达式直接提取邮箱,邮箱提取很简单.只需要一条命令:
grep -E -o '([a-zA-Z0-9_\-\.\+]+)*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}' xxx.txt >> goodmail.txt
注:说明一下,使用 grep 的 -o 和 -E 选项进行正则的精确匹配,其中 -o 表示“only-matching”,即“仅匹配”之意。光用它不够,配合 -E 选项使用扩展正则表达式则威力巨大。哈哈,精准,迅速.快狠准!(命令中的xxx.txt问需要处理的文本,>> 表示追加到后面的 goodmail.txt,如果没有则自动创建此文件,如果需要使用grep)命令多次提取同一类型的字符,请使用单大于符号 > ,表示覆盖.写这些,纯粹是为了小白,我自己就是-_-|)
那么,,我们使用cut 来提取邮箱,也很容易的,先来看看cut命令的介绍:
cut是一个选取命令,就是将一段数据经过分析,取出我们想要的。一般来说,选取信息通常是针对“行”来进行分析的,并不是整篇信息分析的。 (1)其语法格式为: cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file] 使用说明 cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。 如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。 主要参数 -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 -c :以字符为单位进行分割。 -d :自定义分隔符,默认为制表符。 -f :与-d一起使用,指定显示哪个区域。 -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的<br />范围之内,该字符将被写出;否则,该字符将被排除。
在这里,我们只需要一条命令就可以搞定提取邮箱了,直接提取冒号前面的就行,冒号就是界定符.
cut -d ':' -f 1 xxx.txt >> goodmail.txt
那如何提取邮箱后面的字符呢?
cut -d ':' -f 2 xxx.txt >> goodpwd_bad.txt
说明一下,但是没有第二个冒号,那么cut命令发现没有第二个冒号,那么就会使用默认的换行符,即在第一个冒号后的第一个换行符,那么邮箱后面的就取到了.但是因为这个文本并不是标准格式化的,后面还有一些 类似下面的格式 两个单词之间有空格,而我们只需要前面第一个部分.
frdbcgl9676 Standard archie2002 beaver92 Premium bethany7 Standard webbera1 thunder00
这就简单了,在次在此基础上进行cut操作即可:
cut -d ' ' -f 1 goodpwd_bad.txt > goodpwd.txt #注意,两个单引号之间是个空格,并非就是两个单引号凑一起.
如果用awk来处理,稍稍复杂,这需要你会计算两个字符之间的长度,对于像我这种的不规则的,很不好下手...下面简单的举个例子:
echo abcdefghelloword | awk -v head="ab" -v tail="fg" '{print substr($0, index($0,head)+length(head),index($0,tail)-index($0,head)-length(head))}'
#以上关键是计算出开头标记"ab",和结束标记"fg" 在字符串中的位置
#执行结果就是
#cde
其实这三个命令grep,cut,awk,通常是配合管道|和sed命令联合使用,很强大.这就是为啥linux处理文件速度比windows快!
下面附上一些参考文章的链接:
- 理解cut,awk,sort三个命令的分隔符选项: http://blog.csdn.net/u011341352/article/details/52910749
- 多空格&多制表符文本之cut域分割终极方案 : https://sanwen8.cn/p/267AXa4.html
- linux之cut用法: http://www.cnblogs.com/dong008259/archive/2011/12/09/2282679.html
- shell脚本抽取文本文件中指定字符串的方法:sed+grep方法、awk+grep方法(必要时可以联合sed以及grep)、grep+cut方法: http://blog.csdn.net/menlinshuangxi/article/details/7979504
- linux grep命令详解: http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html
- 使用 grep 的 -o 和 -E 选项进行正则的精确匹配: http://blog.sina.com.cn/s/blog_7e9efc570101adbv.html
-
admin 约 11 小时前
@東咩:无
-
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
哥,还能再分享不 百度账号:東咩
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。
-
admin 2024-03-28 22:38
@人大代表:卧槽 别搞我...
-
24年的新闻,你22年爆出来了。厉害了,大哥。

