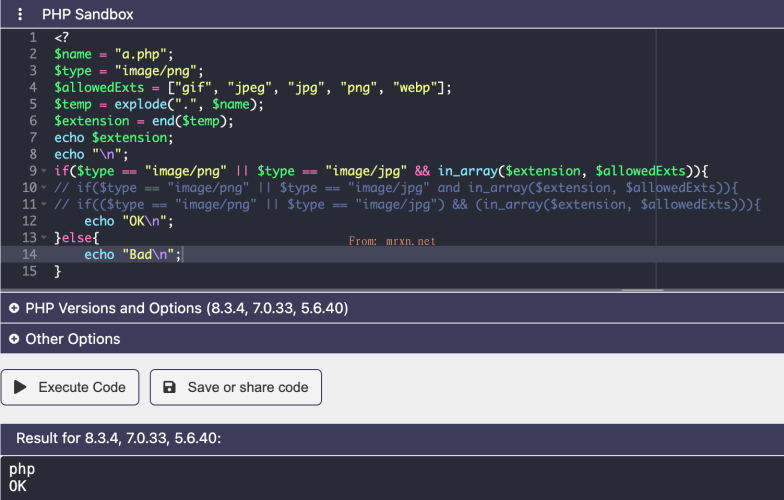
PHP 中与或运算符优先级导致的安全问题 PHP
前言 在 PHP 中,&& 和 || 是逻辑运算符,分别用于逻辑与(AND)和逻辑或(OR)操作。而 and 和 or 也是逻辑运算符,执行相同的基本逻辑操作,但不同之处在于它们的优先级。 简单来说,&& 和 || 的优先级较高,而 and 和 or 的优先级较低。 这意味着,在表达式中,&& 和 || 会先于其他低优先级的运算符(例如赋值运算符 =)进行计...
泛微 e-office v9.0 文件上传漏洞(CNVD-2021-49104) PHP
影响版本:泛微 e-office v9.0
burp 发包:
POST /general/index/UploadFile.php?m=uploadPicture&uploadType=eoffice_logo&userId= HTTP/1.1 Host: 127.0.0.1:7899 User-Agent: Mozilla/5.0 (Windows NT 1...
emlog 6.0特别版的BUG些 emlog
声明:本文仅供爱好者折腾参阅,且由于我这是我很久之前的手记,如有遗漏,表意不明的请多包涵。
一点关于安装出现错误编号2002的可能办法:


第一个就是发文章标签打不上之数据库标签表 emlog_tag
从emlog5.3.1升级过来或者是自己瞎折腾后发现发文章标签打不上或者没了的多半是这个原因。
gid 的值 开头和结尾必须是 英文逗号 不然 问的标签 不能存入 且...
【译】Mysql 中的 "utf8" 编码是个假的 utf-8,请使用 True utf-8 编码:"utf8mb4" 代码人生
注:以下文章为译文,也是我最近遇到的MySQL问题,故摘抄在此做备用,如有侵权,请联系我,我会立即处理。
最近我遇到了一个 bug,我试着通过 Rails 在以“utf8”编码的 MariaDB 中保存一个 UTF-8 字符串,然后出现了一个离奇的错误:
Incorrect string value: ‘\xF0\x 9F \x 98 \x 83 <…’ for column ‘summary’ at row 1
我用的是 UTF-8 编码的客户端,服务器也是 UTF-8 编码的,数据库也是,就连要保存的这个字符串“ <…”也是合法的 UTF-8。
问题的症结在于,MySQL 的“utf8”实际上不是真正的 UTF-8。
“utf8”只支持每个字符最多三个字节,而真正的 UTF-8 是每个字符最多四个字节。
MySQL 一直没有修复这个 bug,他们在 2010 年发布了一个叫作“utf8mb4”的字符集,绕过了这个问题。
当然,他们并没有对新的字符集广而告之(可能是因为这个 bug 让他们觉得很尴尬),以致于现在网络上仍然在建议开发者使用“utf8”,但这些建议都是错误的。
简单概括如下:
-
MySQL 的“utf8mb4”是真正的“UTF-8”。
-
MySQL 的“utf8”是一种“专属的编码”,它能够编码的 Unicode 字符并不多。
我要在这里澄清一下:所有在使用“utf8”的 MySQL 和 MariaDB 用户都应该改用“utf8mb4”,永远都不要再使用“utf8”。
那么什么是编码?什么是 UTF-8?
我们都知道,计算机使用 0 和 1 来存储文本。比如字符“C”被存成“01000011”,那么计算机在显示这个字符时需要经过两个步骤:
-
计算机读取“01000011”,得到数字 67,因为 67 被编码成“01000011”。
-
计算机在 Unicode 字符集中查找 67,找到了“C”。
同样的:
-
我的电脑将“C”映射成 Unicode 字符集中的 67。
-
我的电脑将 67 编码成“01000011”,并发送给 Web 服务器。
几乎所有的网络应用都使用了 Unicode 字符集,因为没有理由使用其他字符集。
Unicode 字符集包含了上百万个字符。最简单的编码是 UTF-32,每个字符使用 32 位。这样做最简单,因为一直以来,计算机将 32 位视为数字,而计算机最在行的就是处理数字。但问题是,这样太浪费空间了。
UTF-8 可以节省空间,在 UTF-8 中,字符“C”只需要 8 位,一些不常用的字符,比如“”需要 32 位。其他的字符可能使用 16 位或 24 位。一篇类似本文这样的文章,如果使用 UTF-8 编码,占用的空间只有 UTF-32 的四分之一左右。
MySQL 的“utf8”字符集与其他程序不兼容,它所谓的“”,可能真的是一坨……
MySQL 简史
为什么 MySQL 开发者会让“utf8”失效?我们或许可以从提交日志中寻找答案。
MySQL 从 4.1 版本开始支持 UTF-8,也就是 2003 年,而今天使用的 UTF-8 标准(RFC 3629)是随后才出现的。
旧版的 UTF-8 标准(RFC 2279)最多支持每个字符 6 个字节。2002 年 3 月 28 日,MySQL 开发者在第一个 MySQL 4.1 预览版中使用了 RFC 2279。
同年 9 月,他们对 MySQL 源代码进行了一次调整:“UTF8 现在最多只支持 3 个字节的序列”。
是谁提交了这些代码?他为什么要这样做?这个问题不得而知。在迁移到 Git 后(MySQL 最开始使用的是 BitKeeper),MySQL 代码库中的很多提交者的名字都丢失了。2003 年 9 月的邮件列表中也找不到可以解释这一变更的线索。
不过我可以试着猜测一下。
2002 年,MySQL 做出了一个决定:如果用户可以保证数据表的每一行都使用相同的字节数,那么 MySQL 就可以在性能方面来一个大提升。为此,用户需要将文本列定义为“CHAR”,每个“CHAR”列总是拥有相同数量的字符。如果插入的字符少于定义的数量,MySQL 就会在后面填充空格,如果插入的字符超过了定义的数量,后面超出部分会被截断。
MySQL 开发者在最开始尝试 UTF-8 时使用了每个字符 6 个字节,CHAR(1) 使用 6 个字节,CHAR(2) 使用 12 个字节,并以此类推。
应该说,他们最初的行为才是正确的,可惜这一版本一直没有发布。但是文档上却这么写了,而且广为流传,所有了解 UTF-8 的人都认同文档里写的东西。
不过很显然,MySQL 开发者或厂商担心会有用户做这两件事:
-
使用 CHAR 定义列(在现在看来,CHAR 已经是老古董了,但在那时,在 MySQL 中使用 CHAR 会更快,不过从 2005 年以后就不是这样子了)。
-
将 CHAR 列的编码设置为“utf8”。
我的猜测是 MySQL 开发者本来想帮助那些希望在空间和速度上双赢的用户,但他们搞砸了“utf8”编码。
所以结果就是没有赢家。那些希望在空间和速度上双赢的用户,当他们在使用“utf8”的 CHAR 列时,实际上使用的空间比预期的更大,速度也比预期的慢。而想要正确性的用户,当他们使用“utf8”编码时,却无法保存像“”这样的字符。
在这个不合法的字符集发布了之后,MySQL 就无法修复它,因为这样需要要求所有用户重新构建他们的数据库。最终,MySQL 在 2010 年重新发布了“utf8mb4”来支持真正的 UTF-8。
为什么这件事情会让人如此抓狂
因为这个问题,我整整抓狂了一个礼拜。我被“utf8”愚弄了,花了很多时间才找到这个 bug。但我一定不是唯一的一个,网络上几乎所有的文章都把“utf8”当成是真正的 UTF-8。
“utf8”只能算是个专有的字符集,它给我们带来了新问题,却一直没有得到解决。
总结
如果你在使用 MySQL 或 MariaDB,不要用“utf8”编码,改用“utf8mb4”。这里(https://mathiasbynens.be/notes/mysql-utf8mb4#utf8-to-utf8mb4)提供了一个指南用于将现有数据库的字符编码从“utf8”转成“utf8mb4”。
英文原文:https://medium.com/@adamhooper/in-mysql-never-use-utf8-use-utf8mb4-11761243e434
原文作者:Adam Hooper
翻译原文:https://www.infoq.cn/article/in-mysql-never-use-utf8-use-utf8
译文作者:无明
emlog5.3.1升级到emlog6.0啦 emlog

今天登录后台发现有emlog6.0了,就去论坛看了下,结果那多这个懒虫并没有写emlog5.3.1升级到emlog6.0的脚本。不过在邻居星知苑哪里看到了,他也发布到了论坛里,这么勤劳,表扬一下,嘿嘿嘿-_- ,对比下emlog5.3.1和emlog6.0.0发现程序变化不大,主要是对tag标签进行了优化。如果经常关注emlog升级的朋友也许知道,我的邻居老司机-flyer在今年早些时候也搞过自制版和特别版的emlog6.0.升级步骤以及脚本如下:
升级方法:
1、确定程序是emlog5.3.1(本程序是对照5.3.1和6.0.0做的);
2、备份网站系统和数据库(非常重要);
3、把update.php上传到网站根目录,同config.php同一个目录;
4、浏览器访问update,按照提示输入数据库密码,确认等待升级完成;
5、上传emlog 6.0.0程序并覆盖,config.php和install.php不要上传。
6、进入博客后台,更新缓存,然后删除update.php
update下载地址:
emlog在nginx下设置伪静态的方法 emlog
今天把停了半年的博客又重新放出来了.换了个机器,故环境变了,不是apache了,之前的.htaccess配置在nginx下就没用了.所以就重新找到了方法,记录一下在nginx下设置emlog的伪静态规则:
引入自定义emlog伪静态nginx规则文件。假如没有emlog.conf文件,你可以在nginx配置文件夹里新建一个emlog.conf文件。内容如下:
location / {
index index.php index.html;
if (!-e $request_filename)
{
rewrite ^/(.+)$ /index.php last;
}
}
然后我们在nginx.conf引入这个伪静态规则即可.include emlog.conf;
然后重启nginx,service nginx reload .
shell编程报错:“syntax error near unexpected token `” 代码人生
因为测试exp...在Kali测试正常....不小心在windows下用sublime编辑了一下...再去linux运行就出错了..
运行报错syntax error near unexpected token `..
左看右看shell脚本没有问题,没有办法google搜索,发现一位仁兄讲的挺好,内容如下:
用命令vi -b 打开你的SHELL脚本文件,你会。发现每行脚本最后多了个^M。
那么接下来就要搞清楚这个^M是什么东东?
long long ago..... 老式的电传打字机使用两个字符来另起新行。一个字符把滑动架移回首位 (称为回车,<CR>,ASCII码为0D),另一个字符把纸上移一行 (称为换行, <LF>,ASCII码为0A)。当计算机问世以后,存储器曾经非常昂贵。有些人就认定没必要用两个字符来表示行尾。UNIX 开发者决定他们可以用 一个字符来表示行尾,Linux沿袭Unix,也是<LF>。Apple 开发者规定了用<CR>。开发 MS-DOS以及Windows 的那些家伙则决定沿用老式的<CR><LF>。
因为MS-DOS及Windows是回车+换行来表示换行,因此在Linux下用Vim查看在Windows下用VC写的代码,行尾后的“^M”符号,表示的是符。
在Vim中解决这个问题,很简单,在Vim中利用替换功能就可以将“^M”都干掉,键入如下替换命令行:
1)vi -b setup.sh
2)在命令编辑行<就是: 按ESC键 然后shift+:冒号>输入:%s/^M//g
注意:上述命令行中的“^M”符,不是“^”再加上“M”,而是由“Ctrl+v”、“Ctrl+M”键生成的。
这样替换掉以后,保存就可以执行了。当然还有其他的替换方式比如:
a.一些linux版本有 dos2unix 程序,可以用来祛除^M。
b.cat filename1 | tr -d "/r" > newfile 去掉^M生成一个新文件,还有sed命令等,凡是可以替换的命令都是可以用来新生成一个文件的。
按照上面所说的,删除^M后 ,shell脚本就运行正常.切记.sh脚本不要再Windows下编辑...各种诡异的错误...
PS:另外小计一下在测试exp时候,
执行curl -sSL 提示curl: (35) SSL connect error ,解决方法----
升级网络安全服务即可(centos): yum update nss.
Discuz 加密解密函数 authcode PHP
<?php
/**
* $string 明文或密文
* $operation 加密ENCODE或解密DECODE
* $key 密钥
* $expiry 密钥有效期
*/
function authcode($string, $operation = 'DECODE', $key = '', $expiry = 0) {
// 动态密匙长度,相同的明文会生成不同密文就是依靠动态密匙
// 加入随机密钥,可以令密文无任何规律,即便是原文和密钥完全相同,加密结果也会每次不同,增大破解难度。
// 取值越大,密文变动规律越大,密文变化 = 16 的 $ckey_length 次方
// 当此值为 0 时,则不产生随机密钥
$ckey_length = 4;
// 密匙
// $GLOBALS['discuz_auth_key'] 这里可以根据自己的需要修改
$key = md5($key ? $key : $GLOBALS['discuz_auth_key']);
// 密匙a会参与加解密
$keya = md5(substr($key, 0, 16));
// 密匙b会用来做数据完整性验证
$keyb = md5(substr($key, 16, 16));
// 密匙c用于变化生成的密文
$keyc = $ckey_length ? ($operation == 'DECODE' ? substr($string, 0, $ckey_length): substr(md5(microtime()), -$ckey_length)) : '';
// 参与运算的密匙
$cryptkey = $keya.md5($keya.$keyc);
$key_length = strlen($cryptkey);
// 明文,前10位用来保存时间戳,解密时验证数据有效性,10到26位用来保存$keyb(密匙b),解密时会通过这个密匙验证数据完整性
// 如果是解码的话,会从第$ckey_length位开始,因为密文前$ckey_length位保存 动态密匙,以保证解密正确
$string = $operation == 'DECODE' ? base64_decode(substr($string, $ckey_length)) : sprintf('%010d', $expiry ? $expiry + time() : 0).substr(md5($string.$keyb), 0, 16).$string;
$string_length = strlen($string);
$result = '';
$box = range(0, 255);
$rndkey = array();
// 产生密匙簿
for($i = 0; $i <= 255; $i++) {
$rndkey[$i] = ord($cryptkey[$i % $key_length]);
}
// 用固定的算法,打乱密匙簿,增加随机性,好像很复杂,实际上并不会增加密文的强度
for($j = $i = 0; $i < 256; $i++) {
$j = ($j + $box[$i] + $rndkey[$i]) % 256;
$tmp = $box[$i];
$box[$i] = $box[$j];
$box[$j] = $tmp;
}
// 核心加解密部分
for($a = $j = $i = 0; $i < $string_length; $i++) {
$a = ($a + 1) % 256;
$j = ($j + $box[$a]) % 256;
$tmp = $box[$a];
$box[$a] = $box[$j];
$box[$j] = $tmp;
// 从密匙簿得出密匙进行异或,再转成字符
$result .= chr(ord($string[$i]) ^ ($box[($box[$a] + $box[$j]) % 256]));
}
if($operation == 'DECODE') {
// substr($result, 0, 10) == 0 验证数据有效性
// substr($result, 0, 10) - time() > 0 验证数据有效性
// substr($result, 10, 16) == substr(md5(substr($result, 26).$keyb), 0, 16) 验证数据完整性
// 验证数据有效性,请看未加密明文的格式
if((substr($result, 0, 10) == 0 || substr($result, 0, 10) - time() > 0) && substr($result, 10, 16) == substr(md5(substr($result, 26).$keyb), 0, 16)) {
return substr($result, 26);
} else {
return '';
}
} else {
// 把动态密匙保存在密文里,这也是为什么同样的明文,生产不同密文后能解密的原因
// 因为加密后的密文可能是一些特殊字符,复制过程可能会丢失,所以用base64编码
return $keyc.str_replace('=', '', base64_encode($result));
}
}
$a = "mrxn.net";
$b = authcode($a, "ENCODE", "abc123");
echo $b."<br/>";
echo authcode($b, "DECODE", "abc123");
?>
运行效果如下:
4582HxrlipjHXFJ8fCB42AzZN6N0A/S07AFgev8swj1a6Qy/fxhuJFM
mrxn.net
注:因学习需要,转载挡笔记.文章来源于网络.
HP的$_SERVER['HTTP_HOST']获取服务器地址功能详解 PHP
uchome的index文件中的二级域名功能判断,使用了php的$_SERVER['HTTP_HOST'],开始对这个不是很了解,所以百度了一下,发现一篇帖子有点意思,转发过来做个记录。
在php中,我们一般通过$_SERVER['HTTP_HOST']来活得URL中网站的域名或者ip地址。
php手册中的解释如下:
“HTTP_HOST”
当前请求的 Host: 头信息的内容。
一般来说,这样子不会遇到什么问题,在一些常见的php框架中,如PFC3和FLEA也是基于该预定义变量。
然而最近在做的一个项目,程序移交到客户手里测试时,竟然发现程序的跳转总是会出错。
最后找出原因:$_SERVER['HTTP_HOST']在客户的环境里,取得的值总是程序所在的服务器在其局域网内的ip值。
究其原因,是因为,客户的公司通过一台服务器连接至因特网,而我们的程序所在的服务器,是通过域名映射出来的,也就是中间有个“代理”的过程。因此$_SERVER['HTTP_HOST']在这样的环境里,取得的值总是程序所在的服务器在其局域网内的ip值。
最后查了不少资料,在symfony框架里面,找到替代的实现方法:
将
$host = $_SERVER['HTTP_HOST'];
替换成:
$host = isset($_SERVER['HTTP_X_FORWARDED_HOST']) ? $_SERVER['HTTP_X_FORWARDED_HOST'] : (isset($_SERVER['HTTP_HOST']) ? $_SERVER['HTTP_HOST'] : '');
即可。
注:我刚好遇到这个问题,所以搜索找到了这篇文章,故转载以当作笔记.
原文地址:https://www.oschina.net/question/36370_14769
代码审校工程师系列之-PHP漏洞发掘及代码防御 PHP
教程来自一位想我求助解压密码的读者,我大致看了一下是2011年左右的,具体的是谁出的教程不知道,不过,作为学习PHP代码审计的还是不错。特地在此分享一下,课程目录如下:
解压密码合集.txt Seay-Svn源代码泄露漏洞利用工具.rar 新浪web安全培训.ppt Seay源代码审计系统2.0.rar 第3课sql注入及防护(2).rar 第1课课程环境搭建.rar 第2课sql注入及防护.rar 第7课文件包含漏洞及代码防御.rar 第10课反射型XSS漏洞和防御.rar 第5课命令执行漏洞及代码防御.rar 第17课打造自己的php防御代码.rar 第6课命令执行漏洞实践防御.rar 第11课存储型XSS漏洞和实践.rar 第16课php函数漏洞及代码防御.rar 第9课CSRF漏洞和防御.rar 第8课文件包含漏洞实战挖掘.rar 第13课php文件上传漏洞和代码防御2.rar 第4课sql注入及防护(3).rar 第12课php文件上传漏洞和代码防御.rar 第18课php安全配置加固.rar 第14课php文件上传漏洞代码分析及防御实践.rar 第15课通过7种方式分析php获取webshell漏洞.rar下载链接:点我传送,如果失效,请联系我更改。
-
admin 约 10 小时前
@小白:感谢 文章对你有帮助我的写作就是有价值的
-
小白 约 19 小时前
博主牛牛牛牛,完美解决,小白们记得搜索的时候把(=false...
-
@東咩:无
-
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
哥,还能再分享不 百度账号:東咩
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。

