【译】Mysql 中的 "utf8" 编码是个假的 utf-8,请使用 True utf-8 编码:"utf8mb4" 代码人生
注:以下文章为译文,也是我最近遇到的MySQL问题,故摘抄在此做备用,如有侵权,请联系我,我会立即处理。
最近我遇到了一个 bug,我试着通过 Rails 在以“utf8”编码的 MariaDB 中保存一个 UTF-8 字符串,然后出现了一个离奇的错误:
Incorrect string value: ‘\xF0\x 9F \x 98 \x 83 <…’ for column ‘summary’ at row 1
我用的是 UTF-8 编码的客户端,服务器也是 UTF-8 编码的,数据库也是,就连要保存的这个字符串“ <…”也是合法的 UTF-8。
问题的症结在于,MySQL 的“utf8”实际上不是真正的 UTF-8。
“utf8”只支持每个字符最多三个字节,而真正的 UTF-8 是每个字符最多四个字节。
MySQL 一直没有修复这个 bug,他们在 2010 年发布了一个叫作“utf8mb4”的字符集,绕过了这个问题。
当然,他们并没有对新的字符集广而告之(可能是因为这个 bug 让他们觉得很尴尬),以致于现在网络上仍然在建议开发者使用“utf8”,但这些建议都是错误的。
简单概括如下:
-
MySQL 的“utf8mb4”是真正的“UTF-8”。
-
MySQL 的“utf8”是一种“专属的编码”,它能够编码的 Unicode 字符并不多。
我要在这里澄清一下:所有在使用“utf8”的 MySQL 和 MariaDB 用户都应该改用“utf8mb4”,永远都不要再使用“utf8”。
那么什么是编码?什么是 UTF-8?
我们都知道,计算机使用 0 和 1 来存储文本。比如字符“C”被存成“01000011”,那么计算机在显示这个字符时需要经过两个步骤:
-
计算机读取“01000011”,得到数字 67,因为 67 被编码成“01000011”。
-
计算机在 Unicode 字符集中查找 67,找到了“C”。
同样的:
-
我的电脑将“C”映射成 Unicode 字符集中的 67。
-
我的电脑将 67 编码成“01000011”,并发送给 Web 服务器。
几乎所有的网络应用都使用了 Unicode 字符集,因为没有理由使用其他字符集。
Unicode 字符集包含了上百万个字符。最简单的编码是 UTF-32,每个字符使用 32 位。这样做最简单,因为一直以来,计算机将 32 位视为数字,而计算机最在行的就是处理数字。但问题是,这样太浪费空间了。
UTF-8 可以节省空间,在 UTF-8 中,字符“C”只需要 8 位,一些不常用的字符,比如“”需要 32 位。其他的字符可能使用 16 位或 24 位。一篇类似本文这样的文章,如果使用 UTF-8 编码,占用的空间只有 UTF-32 的四分之一左右。
MySQL 的“utf8”字符集与其他程序不兼容,它所谓的“”,可能真的是一坨……
MySQL 简史
为什么 MySQL 开发者会让“utf8”失效?我们或许可以从提交日志中寻找答案。
MySQL 从 4.1 版本开始支持 UTF-8,也就是 2003 年,而今天使用的 UTF-8 标准(RFC 3629)是随后才出现的。
旧版的 UTF-8 标准(RFC 2279)最多支持每个字符 6 个字节。2002 年 3 月 28 日,MySQL 开发者在第一个 MySQL 4.1 预览版中使用了 RFC 2279。
同年 9 月,他们对 MySQL 源代码进行了一次调整:“UTF8 现在最多只支持 3 个字节的序列”。
是谁提交了这些代码?他为什么要这样做?这个问题不得而知。在迁移到 Git 后(MySQL 最开始使用的是 BitKeeper),MySQL 代码库中的很多提交者的名字都丢失了。2003 年 9 月的邮件列表中也找不到可以解释这一变更的线索。
不过我可以试着猜测一下。
2002 年,MySQL 做出了一个决定:如果用户可以保证数据表的每一行都使用相同的字节数,那么 MySQL 就可以在性能方面来一个大提升。为此,用户需要将文本列定义为“CHAR”,每个“CHAR”列总是拥有相同数量的字符。如果插入的字符少于定义的数量,MySQL 就会在后面填充空格,如果插入的字符超过了定义的数量,后面超出部分会被截断。
MySQL 开发者在最开始尝试 UTF-8 时使用了每个字符 6 个字节,CHAR(1) 使用 6 个字节,CHAR(2) 使用 12 个字节,并以此类推。
应该说,他们最初的行为才是正确的,可惜这一版本一直没有发布。但是文档上却这么写了,而且广为流传,所有了解 UTF-8 的人都认同文档里写的东西。
不过很显然,MySQL 开发者或厂商担心会有用户做这两件事:
-
使用 CHAR 定义列(在现在看来,CHAR 已经是老古董了,但在那时,在 MySQL 中使用 CHAR 会更快,不过从 2005 年以后就不是这样子了)。
-
将 CHAR 列的编码设置为“utf8”。
我的猜测是 MySQL 开发者本来想帮助那些希望在空间和速度上双赢的用户,但他们搞砸了“utf8”编码。
所以结果就是没有赢家。那些希望在空间和速度上双赢的用户,当他们在使用“utf8”的 CHAR 列时,实际上使用的空间比预期的更大,速度也比预期的慢。而想要正确性的用户,当他们使用“utf8”编码时,却无法保存像“”这样的字符。
在这个不合法的字符集发布了之后,MySQL 就无法修复它,因为这样需要要求所有用户重新构建他们的数据库。最终,MySQL 在 2010 年重新发布了“utf8mb4”来支持真正的 UTF-8。
为什么这件事情会让人如此抓狂
因为这个问题,我整整抓狂了一个礼拜。我被“utf8”愚弄了,花了很多时间才找到这个 bug。但我一定不是唯一的一个,网络上几乎所有的文章都把“utf8”当成是真正的 UTF-8。
“utf8”只能算是个专有的字符集,它给我们带来了新问题,却一直没有得到解决。
总结
如果你在使用 MySQL 或 MariaDB,不要用“utf8”编码,改用“utf8mb4”。这里(https://mathiasbynens.be/notes/mysql-utf8mb4#utf8-to-utf8mb4)提供了一个指南用于将现有数据库的字符编码从“utf8”转成“utf8mb4”。
英文原文:https://medium.com/@adamhooper/in-mysql-never-use-utf8-use-utf8mb4-11761243e434
原文作者:Adam Hooper
翻译原文:https://www.infoq.cn/article/in-mysql-never-use-utf8-use-utf8
译文作者:无明
关于SQL中join的各种用法总结 技术文章
首先声明:文章来源于国外的 codeproject 我这里只是由于复习SQL的时候需要就Google搜索[可以用我个人搭建的Google搜索供大家搜索文章学习使用]了一下,找到这篇文章,再次做个简单的记录同时也方便以后的有缘人,如有侵权的地方还请来信注明,感谢原文的作者的勤劳付出,留下如此详细全面的关于SQL的join的用法。
codeproject是国外一个免费的可以公开自己写的代码与程序的优秀网站有点类似于GitHub只不过是社区版,在这个网站所有用户都可以发布自己写过的代码,程序,或者是详细的文档说明。比国内的cnblog、csdn都要好,如果要说缺点的话,就是全英文的,当然大部分还是比较容易理解的。但是codeproject也有中文区: https://www.codeproject.com/Forums/1580230/General-Chinese-Topics.aspx ,感兴趣的可以去注册玩。
我们先用一张图来看一下 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 等七种 join 相关的用法:

下面分开说明这七种用法,先说第一种:
1.INNER JOIN(内连接)

这是最简单,最容易理解的Join,也是最常见的。此查询将返回左表(表A)中右表(表B)中都具有匹配记录的所有记录(共同拥有的相同的部分)。此Join用法的代码大致如下:
SELECT <select_list> FROM Table_A A INNER JOIN Table_B B ON A.Key = B.Key
2.LEFT JOIN(左连接)

LEFT JOIN 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行。此Join用法的代码大致如下:
SELECT <select_list> FROM Table_A A LEFT JOIN Table_B B ON A.Key = B.Key
3.RIGHT JOIN(右连接)

RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。此Join用法的代码大致如下:
SELECT <select_list> FROM Table_A A RIGHT JOIN Table_B B ON A.Key = B.Key
4.OUTER JOIN(外连接)

FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行. FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。此Join用法的代码大致如下:
SELECT <select_list> FROM Table_A A FULL OUTER JOIN Table_B B ON A.Key = B.Key
5.LEFT JOIN EXCLUDING INNER JOIN(左连接-内连接)

此查询将返回左表(表A)中与右表(表B)中的任何记录都不匹配的所有记录。此Join的编写如下:
SELECT <select_list> FROM Table_A A LEFT JOIN Table_B B ON A.Key = B.Key WHERE B.Key IS NULL
6.RIGHT JOIN EXCLUDING INNER JOIN(右连接-内连接)

此查询将返回右表(表B)中与左表(表A)中的任何记录都不匹配的所有记录。此Join的编写如下:
SELECT <select_list> FROM Table_A A RIGHT JOIN Table_B B ON A.Key = B.Key WHERE A.Key IS NULL
7.OUTER JOIN EXCLUDING INNER JOIN(外连接-内连接)

此查询将返回左表(表A)中的所有记录以及右表(表B)中都不匹配的所有记录。我还没有需要使用这种类型的Join,但是其他的类型,我经常使用。此Join的编写如下:
SELECT <select_list> FROM Table_A A FULL OUTER JOIN Table_B B ON A.Key = B.Key WHERE A.Key IS NULL OR B.Key IS NULL
下面举一些例子:
TABLE_A PK Value ---- ---------- 1 FOX 2 COP 3 TAXI 6 WASHINGTON 7 DELL 5 ARIZONA 4 LINCOLN 10 LUCENT TABLE_B PK Value ---- ---------- 1 TROT 2 CAR 3 CAB 6 MONUMENT 7 PC 8 MICROSOFT 9 APPLE 11 SCOTCH这七种连接方式的结果如下所示:
-- INNER JOIN
SELECT A.PK AS A_PK, A.Value AS A_Value,
B.Value AS B_Value, B.PK AS B_PK
FROM Table_A A
INNER JOIN Table_B B
ON A.PK = B.PK
A_PK A_Value B_Value B_PK
---- ---------- ---------- ----
1 FOX TROT 1
2 COP CAR 2
3 TAXI CAB 3
6 WASHINGTON MONUMENT 6
7 DELL PC 7
(5 row(s) affected)
-- LEFT JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A LEFT JOIN Table_B B ON A.PK = B.PK A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- 1 FOX TROT 1 2 COP CAR 2 3 TAXI CAB 3 4 LINCOLN NULL NULL 5 ARIZONA NULL NULL 6 WASHINGTON MONUMENT 6 7 DELL PC 7 10 LUCENT NULL NULL (8 row(s) affected)
-- RIGHT JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A RIGHT JOIN Table_B B ON A.PK = B.PK A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- 1 FOX TROT 1 2 COP CAR 2 3 TAXI CAB 3 6 WASHINGTON MONUMENT 6 7 DELL PC 7 NULL NULL MICROSOFT 8 NULL NULL APPLE 9 NULL NULL SCOTCH 11 (8 row(s) affected)
-- OUTER JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A FULL OUTER JOIN Table_B B ON A.PK = B.PK A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- 1 FOX TROT 1 2 COP CAR 2 3 TAXI CAB 3 6 WASHINGTON MONUMENT 6 7 DELL PC 7 NULL NULL MICROSOFT 8 NULL NULL APPLE 9 NULL NULL SCOTCH 11 5 ARIZONA NULL NULL 4 LINCOLN NULL NULL 10 LUCENT NULL NULL (11 row(s) affected)
-- LEFT EXCLUDING JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A LEFT JOIN Table_B B ON A.PK = B.PK WHERE B.PK IS NULL A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- 4 LINCOLN NULL NULL 5 ARIZONA NULL NULL 10 LUCENT NULL NULL (3 row(s) affected)
-- RIGHT EXCLUDING JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A RIGHT JOIN Table_B B ON A.PK = B.PK WHERE A.PK IS NULL A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- NULL NULL MICROSOFT 8 NULL NULL APPLE 9 NULL NULL SCOTCH 11 (3 row(s) affected)
-- OUTER EXCLUDING JOIN SELECT A.PK AS A_PK, A.Value AS A_Value, B.Value AS B_Value, B.PK AS B_PK FROM Table_A A FULL OUTER JOIN Table_B B ON A.PK = B.PK WHERE A.PK IS NULL OR B.PK IS NULL A_PK A_Value B_Value B_PK ---- ---------- ---------- ---- NULL NULL MICROSOFT 8 NULL NULL APPLE 9 NULL NULL SCOTCH 11 5 ARIZONA NULL NULL 4 LINCOLN NULL NULL 10 LUCENT NULL NULL (6 row(s) affected)注:原文连接:https://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
MySQL 在 SELECT 的同时 UPDATE 同一张表 技术文章
MySQL 不允许 SELECT FROM 后面指向用作 UPDATE 的表,有时候让人纠结。当然,有比创建无休止的临时表更好的办法。本文解释如何 UPDATE 一张表,同时在查询子句中使用 SELECT.
问题描述
假设我要 UPDATE 的表跟查询子句是同一张表,这样做有许多种原因,例如用统计数据更新表的字段(此时需要用 group 子句返回统计值),从某一条记录的字段 update 另一条记录,而不必使用非标准的语句,等等。举个例子:
create table apples(variety char(10) primary key, price int);
insert into apples values('fuji', 5), ('gala', 6);
update apples
set price = (select price from apples where variety = 'gala')
where variety = 'fuji';
错误提示是:ERROR 1093 (HY000): You can't specify target table'apples' for update in FROM clause. MySQL 手册 UPDATE documentation 这下面有说明 : “Currently, you cannot update a table and select from the same table in a subquery.”
在这个例子中,要解决问题也十分简单,但有时候不得不通过查询子句来 update 目标。好在我们有办法。
解决办法
既然 MySQL 是通过临时表来实现 FROM 子句里面的嵌套查询,那么把嵌套查询装进另外一个嵌套查询里,可使 FROM 子句查询和保存都是在临时表里进行,然后间接地在外围查询被引用。下面的语句是正确的:
update apples
set price = (
select price from (
select * from apples
) as x
where variety = 'gala')
where variety = 'fuji';
如果你想了解更多其中的机制,请阅读 MySQL Internals Manual 相关章节。
没有解决的问题
一个常见的问题是,IN() 子句优化废品,被重写成相关的嵌套查询,有时(往往?)造成性能低下。把嵌套查询装进另外一个嵌套查询里并不能阻止它重写成相关嵌套,除非我下狠招。这种情况下,最好用 JOIN 重构查询(rewrite such a query as a join)。
另一个没解决的问题是临时表被引用多次。“装进嵌套查询” 的技巧无法解决这些问题,因为它们在编译时被创建,而上面讨论的 update 问题是在运行时。(译者注:个人认为跟文章讨论的主题没几毛钱关系)
原文地址:http://www.xaprb.com/blog/2006/06/23/how-to-select-from-an-update-target-in-mysql/
MySQL 如何查找并删除重复行? 技术文章
如何查找重复行
第一步是定义什么样的行才是重复行。多数情况下很简单:它们某一列具有相同的值。本文采用这一定义,或许你对“重复”的定义比这复杂,你需要对sql做些修改。
本文要用到的数据样本
create table test(id int not null primary key, day date not null); insert into test(id, day) values(1, '2006-10-08'); insert into test(id, day) values(2, '2006-10-08'); insert into test(id, day) values(3, '2006-10-09'); select * from test; +----+------------+ | id | day | +----+------------+ | 1 | 2006-10-08 | | 2 | 2006-10-08 | | 3 | 2006-10-09 | +----+------------+
前面两行在day字段具有相同的值,因此如何我将他们当做重复行,这里有一查询语句可以查找。查询语句使用GROUP BY子句把具有相同字段值的行归为一组,然后计算组的大小。
select day, count(*) from test GROUP BY day; +------------+----------+ | day | count(*) | +------------+----------+ | 2006-10-08 | 2 | | 2006-10-09 | 1 | +------------+----------+
重复行的组大小大于1。如何希望只显示重复行,必须使用HAVING子句,比如
select day, count(*) from test group by day HAVING count(*) > 1; +------------+----------+ | day | count(*) | +------------+----------+ | 2006-10-08 | 2 | +------------+----------+
这是基本的技巧:根据具有相同值的字段分组,然后知显示大小大于1的组。
为什么不能使用WHERE子句?
因为WHERE子句过滤的是分组之前的行,HAVING子句过滤的是分组之后的行。
如何删除重复行
一个相关的问题是如何删除重复行。一个常见的任务是,重复行只保留一行,其他删除,然后你可以创建适当的索引,防止以后再有重复的行写入数据库。
同样,首先是弄清楚重复行的定义。你要保留的是哪一行呢?第一行,或者某个字段具有最大值的行?本文中,假设要保留的是第一行——id字段具有最小值的行,意味着你要删除其他的行。
也许最简单的方法是通过临时表。尤其对于MYSQL,有些限制是不能在一个查询语句中select的同时update一个表。在我的另一篇文章中 MySQL 在 SELECT 的同时 UPDATE 同一张表(How to select from an update target in MySQL), 讲述了如何绕过这些限制。简单起见,这里只用到了临时表的方法。
我们的任务是:删除所有重复行,除了分组中id字段具有最小值的行。因此,需要找出大小大于1的分组,以及希望保留的行。你可以使用MIN()函数。这里的语句是创建临时表,以及查找需要用DELETE删除的行。
create temporary table to_delete (day date not null, min_id int not null); insert into to_delete(day, min_id) select day, MIN(id) from test group by day having count(*) > 1; select * from to_delete; +------------+--------+ | day | min_id | +------------+--------+ | 2006-10-08 | 1 | +------------+--------+
有了这些数据,你可以开始删除“脏数据”行了。可以有几种方法,各有优劣(详见我的文章many-to-one problems in SQL),但这里不做详细比较,只是说明在支持查询子句的关系数据库中,使用的标准方法。
delete from test
where exists(
select * from to_delete
where to_delete.day = test.day and to_delete.min_id <> test.id
)
如何查找多列上的重复行
有人最近问到这样的问题:
我的一个表上有两个字段b和c,分别关联到其他两个表的b和c字段。我想要找出在b字段或者c字段上具有重复值的行。
咋看很难明白,通过对话后我理解了:他想要对b和c分别创建unique索引。如上所述,查找在某一字段上具有重复值的行很简单,只要用group分组,然后计算组的大小。并且查找全部字段重复的行也很简单,只要把所有字段放到group子句。但如果是判断b字段重复或者c字段重复,问题困难得多。这里提问者用到的样本数据
create table a_b_c( a int not null primary key auto_increment, b int, c int ); insert into a_b_c(b,c) values (1, 1); insert into a_b_c(b,c) values (1, 2); insert into a_b_c(b,c) values (1, 3); insert into a_b_c(b,c) values (2, 1); insert into a_b_c(b,c) values (2, 2); insert into a_b_c(b,c) values (2, 3); insert into a_b_c(b,c) values (3, 1); insert into a_b_c(b,c) values (3, 2); insert into a_b_c(b,c) values (3, 3);
现在,你可以轻易看到表里面有一些重复的行,但找不到两行具有相同的二元组{b, c}。这就是为什么问题会变得困难了。
错误的查询语句
如果把两列放在一起分组,你会得到不同的结果,具体看如何分组和计算大小。提问者恰恰是困在了这里。有时候查询语句找到一些重复行却漏了其他的。这是他用到了查询
select b, c, count(*) from a_b_c group by b, c having count(distinct b > 1) or count(distinct c > 1);
结果返回所有的行,因为CONT(*)总是1.为什么?因为 >1 写在COUNT()里面。这个错误很容易被忽略,事实上等效于
select b, c, count(*) from a_b_c group by b, c having count(1) or count(1);
为什么?因为 (b> 1) 是一个布尔值,根本不是你想要的结果。你要的是:
select b, c, count(*) from a_b_c
group by b, c
having count(distinct b) > 1
or count(distinct c) > 1;
返回空结果。很显然,因为没有重复的{b,c}。这人试了很多其他的OR和AND的组合,用来分组的是一个字段,计算大小的是另一个字段,像这样
select b, count(*) from a_b_c group by b having count(distinct c) > 1; +------+----------+ | b | count(*) | +------+----------+ | 1 | 3 | | 2 | 3 | | 3 | 3 | +------+----------+
没有一个能够找出全部的重复行。而且最令人沮丧的是,对于某些情况,这种语句是有效的,如果错误地以为就是这么写法,然而对于另外的情况,很可能得到错误结果。
事实上,单纯用GROUP BY 是不可行的。为什么?因为当你对某一字段使用group by时,就会把另一字段的值分散到不同的分组里。对这些字段排序可以看到这些效果,正如分组做的那样。首先,对b字段排序,看看它是如何分组的
| a | b | c |
|---|---|---|
| 7 | 1 | 1 |
| 8 | 1 | 2 |
| 9 | 1 | 3 |
| 10 | 2 | 1 |
| 11 | 2 | 2 |
| 12 | 2 | 3 |
| 13 | 3 | 1 |
| 14 | 3 | 2 |
| 15 | 3 | 3 |
当你对b字段排序(分组),相同值的c被分到不同的组,因此不能用COUNT(DISTINCT c)来计算大小。COUNT()之类的内部函数只作用于同一个分组,对于不同分组的行就无能为力了。类似,如果排序的是c字段,相同值的b也会分到不同的组,无论如何是不能达到我们的目的的。
几种正确的方法
也许最简单的方法是分别对某个字段查找重复行,然后用UNION拼在一起,像这样:
select b as value, count(*) as cnt, 'b' as what_col from a_b_c group by b having count(*) > 1 union select c as value, count(*) as cnt, 'c' as what_col from a_b_c group by c having count(*) > 1; +-------+-----+----------+ | value | cnt | what_col | +-------+-----+----------+ | 1 | 3 | b | | 2 | 3 | b | | 3 | 3 | b | | 1 | 3 | c | | 2 | 3 | c | | 3 | 3 | c | +-------+-----+----------+
输出what_col字段为了提示重复的是哪个字段。另一个办法是使用嵌套查询:
select a, b, c from a_b_c
where b in (select b from a_b_c group by b having count(*) > 1)
or c in (select c from a_b_c group by c having count(*) > 1);
+----+------+------+
| a | b | c |
+----+------+------+
| 7 | 1 | 1 |
| 8 | 1 | 2 |
| 9 | 1 | 3 |
| 10 | 2 | 1 |
| 11 | 2 | 2 |
| 12 | 2 | 3 |
| 13 | 3 | 1 |
| 14 | 3 | 2 |
| 15 | 3 | 3 |
+----+------+------+
这种方法的效率要比使用UNION低许多,并且显示每一重复的行,而不是重复的字段值。还有一种方法,将自己跟group的嵌套查询结果联表查询。写法比较复杂,但对于复杂的数据或者对效率有较高要求的情况,是很有必要的。
select a, a_b_c.b, a_b_c.c
from a_b_c
left outer join (
select b from a_b_c group by b having count(*) > 1
) as b on a_b_c.b = b.b
left outer join (
select c from a_b_c group by c having count(*) > 1
) as c on a_b_c.c = c.c
where b.b is not null or c.c is not null
以上方法可行,我敢肯定还有其他的方法。如果UNION能用,我想会是最简单不过的了。
原文地址:https://www.xaprb.com/blog/2006/10/09/how-to-find-duplicate-rows-with-sql/
emlog,连接数据库失败,请检查数据库信息,错误编号 2002 技术文章
今天起来发现博客打不开了,提示:连接数据库失败,请检查数据库信息,错误编号 2002。
首先看这个错误代码是2002,并不是emlog的配置文件有问题,因为从include/lib/mysql.php里面可以看到这个2002应该是MySQL本身出问题了,但是不一定,下面来排查是不是MySQL本身出问题了。
/**
* 内部实例对象
* @var object MySql
*/
private static $instance = null;
private function __construct() {
if (!function_exists('mysql_connect')) {
emMsg('服务器空间PHP不支持MySql数据库');
}
if (!$this->conn = @mysql_connect(DB_HOST, DB_USER, DB_PASSWD)) {
switch ($this->geterrno()) {
case 2005:
emMsg("连接数据库失败,数据库地址错误或者数据库服务器不可用");
break;
case 2003:
emMsg("连接数据库失败,数据库端口错误");
break;
case 2006:
emMsg("连接数据库失败,数据库服务器不可用");
break;
case 1045:
emMsg("连接数据库失败,数据库用户名或密码错误");
break;
default :
emMsg("连接数据库失败,请检查数据库信息。错误编号:" . $this->geterrno());
break;
}
}
if ($this->getMysqlVersion() > '4.1') {
mysql_query("SET NAMES 'utf8'");
}
@mysql_select_db(DB_NAME, $this->conn) OR emMsg("连接数据库失败,未找到您填写的数据库");
}
登上服务器,准备登录mysql,mysql -uroot -ppassword,报错如下:
ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2)
然后查看MySQL状态:
root@mrxn:/# service mysqld status● mysqld.service - LSB: start and stop MySQL Loaded: loaded (/etc/init.d/mysqld) Active: active (exited) since Sun 2017-12-24 10:55:03 CST; 5min ago Process: 536 ExecStart=/etc/init.d/mysqld start (code=exited, status=0/SUCCESS)
Dec 24 10:55:03 mrxn.guest mysqld[536]: Starting MySQLDec 24 10:55:03 mrxn.guest mysqld[536]: Couldn't find MySQL server (/usr/bin/mysqld_safe) ... failed!Dec 24 10:55:03 mrxn.guest systemd[1]: Started LSB: start and stop MySQL.
注意看红色的部分,Couldn't find MySQL server (/usr/bin/mysqld_safe) ... failed! 现在可以进一步确定是MySQL本身出问题了。
问题原因就这与MySQL本身没有启动起来。我们先停止MySQL试试:service mysqld stop ,然后查看状态:
root@mrxn:/# service mysqld status● mysqld.service - LSB: start and stop MySQL Loaded: loaded (/etc/init.d/mysqld) Active: inactive (dead) since Sun 2017-12-24 11:01:09 CST; 1s ago Process: 1809 ExecStop=/etc/init.d/mysqld stop (code=exited, status=0/SUCCESS) Process: 536 ExecStart=/etc/init.d/mysqld start (code=exited, status=0/SUCCESS)
Dec 24 10:55:03 mrxn.guest mysqld[536]: Starting MySQLDec 24 10:55:03 mrxn.guest mysqld[536]: Couldn't find MySQL server (/usr/bin/mysqld_safe) ... failed!Dec 24 10:55:03 mrxn.guest systemd[1]: Started LSB: start and stop MySQL.Dec 24 11:01:09 mrxn.guest systemd[1]: Stopping LSB: start and stop MySQL...Dec 24 11:01:09 mrxn.guest mysqld[1809]: MySQL server PID file could not be found! ... failed!Dec 24 11:01:09 mrxn.guest systemd[1]: Stopped LSB: start and stop MySQL.
然后Google搜索上面的红色关键词:Couldn't find MySQL server (/usr/bin/mysqld_safe) ... failed! ,借鉴这个的方法 http://www.cnblogs.com/olinux/p/5546371.html
查看MySQL的my.cnf 在那些位置存在:
root@mrxn:/# mysqld --verbose --help|grep my.cnf2017-12-24 11:02:32 0 [Warning] Using unique option prefix key_buffer instead of key_buffer_size is deprecated and will be removed in a future release. Please use the full name instead.2017-12-24 11:02:32 0 [Note] --secure-file-priv is set to NULL. Operations related to importing and exporting data are disabled2017-12-24 11:02:32 0 [Note] mysqld (mysqld 5.6.37-log) starting as process 1867 ...2017-12-24 11:02:32 1867 [ERROR] Can't find messagefile '/usr/share/mysql/errmsg.sys'2017-12-24 11:02:32 1867 [Warning] Can't create test file /var/lib/mysql/mrxn.lower-test2017-12-24 11:02:32 1867 [Warning] Can't create test file /var/lib/mysql/mrxn.lower-testmysqld: Can't change dir to '/var/lib/mysql/' (Errcode: 2 - No such file or directory)2017-12-24 11:02:32 1867 [Warning] Using unique option prefix myisam-recover instead of myisam-recover-options is deprecated and will be removed in a future release. Please use the full name instead.2017-12-24 11:02:32 1867 [Note] Plugin 'FEDERATED' is disabled.mysqld: Unknown error 11462017-12-24 11:02:32 1867 [ERROR] Can't open the mysql.plugin table. Please run mysql_upgrade to create it./etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf my.cnf, $MYSQL_TCP_PORT, /etc/services, built-in default2017-12-24 11:02:32 1867 [Note] Binlog end2017-12-24 11:02:32 1867 [Note] Shutting down plugin 'CSV'2017-12-24 11:02:32 1867 [Note] Shutting down plugin 'MyISAM'
注意看红色的标注部分,没有那个文件或者路径。用ls -l /var/lib/ 查看下面确实没有mysql文件夹。
那么就新建一个mysql文件夹,并且设置好权限给mysql使用:
mkdir /var/lib/mysql/
chown -R mysql:mysql /var/lib/mysql/
然后删除多余的那个my.cnf :rm /etc/mysql/my.cnf
然后重启MySQL:service mysqld restart ,并且查看MySQL的状态:
root@mrxn:/# service mysqld restartroot@mrxn:/# service mysqld status ● mysqld.service - LSB: start and stop MySQL Loaded: loaded (/etc/init.d/mysqld) Active: active (running) since Sun 2017-12-24 11:09:00 CST; 5s ago Process: 2121 ExecStop=/etc/init.d/mysqld stop (code=exited, status=0/SUCCESS) Process: 2138 ExecStart=/etc/init.d/mysqld start (code=exited, status=0/SUCCESS) CGroup: /system.slice/mysqld.service ├─2153 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir=/data/mysql --pid-file=/data/mysql/mysql.pid └─2992 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=/usr/local/mysql/l...
Dec 24 11:08:59 mrxn.guest systemd[1]: Starting LSB: start and stop MySQL...Dec 24 11:08:59 mrxn.guest mysqld[2138]: Starting MySQLDec 24 11:09:00 mrxn.guest mysqld[2138]: ..Dec 24 11:09:00 mrxn.guest systemd[1]: Started LSB: start and stop MySQL.
就OK了!
然后根据这个错误我发现了是有人在疯狂的扫描我的博客。。。醉了。。。但是我也不知道为嘛MySQL就抽风了,估计是死锁后我去重启,然后它就抽风了-_-|
MySQL order by 排序小计 技术文章
在使用 MySQL 排序的时候,
我想把 考号(字段 kh) 里面从左数第三个(包含第三个)取两个数为 11 的所有结果的 分数(字段 fs)进行 降序排列,可是我用order by出现这样的结果:
前面的有比较小的值(越小不应该在最后么),后面才是按照降序排列的(数据有几千条)...很尴尬, 同样,我如果用升序排列,则前面的是按照升序的排序的,可是最后的几行就不是的...最后的几行有比较小的分数(不应该是越到最后越是最大的分数么),特么真是太尴尬...
MySQL 代码如下:
SELECT kh, xm, fs FROM score WHERE SUBSTRING(kh, 3, 2) = '11' ORDER BY fs DESC
出现类似如下图的结果(这是使用降序的时候),请问该如何写 MySQL 语句?
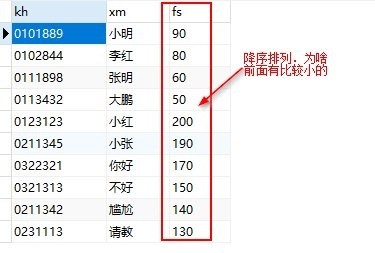
解决办法:我发现我的 FS 字段是 varchar 的 我改成 int 整形在排序也对了,你说的使用 ORDER BY abs(fs) desc 也可以..我不知道 ABS(X)这个函数...
【转载】基于约束的SQL攻击 渗透测试
前言
值得庆幸的是如今开发者在构建网站时,已经开始注重安全问题了。绝大部分开发者都意识到SQL注入漏洞的存在,在本文我想与读者共同去探讨另一种与SQL数据库相关的漏洞,其危害与SQL注入不相上下,但却不太常见。接下来,我将为读者详细展示这种攻击手法,以及相应的防御策略。
注意:本文不是讲述SQL注入攻击
背景介绍
最近,我遇到了一个有趣的代码片段,开发者尝试各种方法来确保数据库的安全访问。当新用户尝试注册时,将运行以下代码:
<?php
// Checking whether a user with the same username exists $username = mysql_real_escape_string($_GET['username']);
$password = mysql_real_escape_string($_GET['password']);
$query = "SELECT *
FROM users
WHERE username='$username'";
$res = mysql_query($query, $database); if($res) { if(mysql_num_rows($res) > 0) { // User exists, exit gracefully
.
.
} else { // If not, only then insert a new entry
$query = "INSERT INTO users(username, password)
VALUES ('$username','$password')";
.
.
}
} 使用以下代码验证登录信息:
<?php
$username = mysql_real_escape_string($_GET['username']);
$password = mysql_real_escape_string($_GET['password']);
$query = "SELECT username FROM users
WHERE username='$username'
AND password='$password' ";
$res = mysql_query($query, $database); if($res) { if(mysql_num_rows($res) > 0){
$row = mysql_fetch_assoc($res); return $row['username'];
}
} return Null; 安全考虑:
过滤用户输入参数了吗? — 完成检查
使用单引号(’)来增加安全性了吗? — 完成检查
按理说应该不会出错了啊?
然而,攻击者依然能够以任意用户身份进行登录!
攻击手法
在谈论这种攻击手法之前,首先我们需要了解几个关键知识点。
-
在SQL中执行字符串处理时,字符串末尾的空格符将会被删除。换句话说“vampire”等同于“vampire ”,对于绝大多数情况来说都是成立的(诸如WHERE子句中的字符串或INSERT语句中的字符串)例如以下语句的查询结果,与使用用户名“vampire”进行查询时的结果是一样的。
SELECT * FROM users WHERE username='vampire ';但也存在异常情况,最好的例子就是LIKE子句了。注意,对尾部空白符的这种修剪操作,主要是在“字符串比较”期间进行的。这是因为,SQL会在内部使用空格来填充字符串,以便在比较之前使其它们的长度保持一致。
-
在所有的INSERT查询中,SQL都会根据varchar(n)来限制字符串的最大长度。也就是说,如果字符串的长度大于“n”个字符的话,那么仅使用字符串的前“n”个字符。比如特定列的长度约束为“5”个字符,那么在插入字符串“vampire”时,实际上只能插入字符串的前5个字符,即“vampi”。
现在,让我们建立一个测试数据库来演示具体攻击过程。
vampire@linux:~$ mysql -u root -p
mysql> CREATE DATABASE testing; Query OK, 1 row affected (0.03 sec) mysql> USE testing; Database changed 接着创建一个数据表users,其包含username和password列,并且字段的最大长度限制为25个字符。然后,我将向username字段插入“vampire”,向password字段插入“my_password”。
mysql> CREATE TABLE users ( -> username varchar(25),
-> password varchar(25)
-> );
Query OK, 0 rows affected (0.09 sec)
mysql> INSERT INTO users
-> VALUES('vampire', 'my_password');
Query OK, 1 row affected (0.11 sec)
mysql> SELECT * FROM users;
+----------+-------------+
| username | password |
+----------+-------------+
| vampire | my_password |
+----------+-------------+ 1 row in set (0.00 sec) 为了展示尾部空白字符的修剪情况,我们可以键入下列命令:
mysql> SELECT * FROM users
-> WHERE username='vampire '; +----------+-------------+ | username | password | +----------+-------------+ | vampire | my_password | +----------+-------------+ 1 row in set (0.00 sec) 现在我们假设一个存在漏洞的网站使用了前面提到的PHP代码来处理用户的注册及登录过程。为了侵入任意用户的帐户(在本例中为“vampire”),只需要使用用户名“vampire[许多空白符]1”和一个随机密码进行注册即可。对于选择的用户名,前25个字符应该只包含vampire和空白字符,这样做将有助于绕过检查特定用户名是否已存在的查询。
mysql> SELECT * FROM users
-> WHERE username='vampire 1';
Empty set (0.00 sec) 需要注意的是,在执行SELECT查询语句时,SQL是不会将字符串缩短为25个字符的。因此,这里将使用完整的字符串进行搜索,所以不会找到匹配的结果。接下来,当执行INSERT查询语句时,它只会插入前25个字符。
mysql> INSERT INTO users(username, password)
-> VALUES ('vampire 1', 'random_pass');
Query OK, 1 row affected, 1 warning (0.05 sec)
mysql> SELECT * FROM users
-> WHERE username='vampire';
+---------------------------+-------------+
| username | password |
+---------------------------+-------------+
| vampire | my_password |
| vampire | random_pass |
+---------------------------+-------------+ 2 rows in set (0.00 sec) 很好,现在我们检索“vampire”的,将返回两个独立用户。注意,第二个用户名实际上是“vampire”加上尾部的18个空格。现在,如果使用用户名“vampire”和密码“random_pass”登录的话,则所有搜索该用户名的SELECT查询都将返回第一个数据记录,也就是原始的数据记录。这样的话,攻击者就能够以原始用户身份登录。这个攻击已经在MySQL和SQLite上成功通过测试。我相信在其他情况下依旧适用。
防御手段
毫无疑问,在进行软件开发时,需要对此类安全漏洞引起注意。我们可采取以下几项措施进行防御:
-
将要求或者预期具有唯一性的那些列加上UNIQUE约束。实际上这是一个涉及软件开发的重要规则,即使你的代码有维持其完整性的功能,也应该恰当的定义数据。由于’username’列具有UNIQUE约束,所以不能插入另一条记录。将会检测到两个相同的字符串,并且INSERT查询将失败。
-
最好使用’id’作为数据库表的主键。并且数据应该通过程序中的id进行跟踪
-
为了更加安全,还可以用手动调整输入参数的限制长度(依照数据库设置)
注:
最好讲MySQL设置成宽松模式,set @@sql_mode=ANSI;即可,还有就是注册时,一般的这种非法的用户名是不能注册的吧。。。不过还是又利用空间的。
文章出自:https://dhavalkapil.com/blogs/SQL-Attack-Constraint-Based/
再次验证百度这SB搜索,还是Google搜索靠谱 技术文章
起因是在论坛看到的一个帖子找智者的博客的一篇文章:如何将将多说评论数据转回EMLOG,但是百度搜索到的都是无法访问的,因为智者的网站服务器出问题了样 有可能是自己折腾死了。。。百度和google在搜索这方面差的太远了。。。下面是对比


都是主机宕机了,可是Google的缓存还是可以用的,可是百度的就玩完了。。。百度取消快照之后,发现变得很鸡肋。。。不知道是不是天朝的原因,怕青少年搜索到了一些不该看的缓存东西,所以让百度取消快照。。。当然都是Mrxn自己瞎掰

还有就是百度今年说对https的支持,但是收录还是一直那鸟样,不收录,没使用https之前,收录很快,现在是每天来,但是不收录,他大爷的就是玩。。。google收录很及时,貌似360搜搜都比百度蜘蛛勤快。度娘,赶紧把蜘蛛鞭打一顿,这么懒!
下面附上将多说数据转回emlog或者是其他博客的教程:
刚刚使用emlog时还在习惯性的使用多说评论,不过发现评论无法同步回本地。所以只能百度下解决办法。(只不过最后我放弃了多说)
使用说明:
1.在多说管理页面导出多说评论
2.解压附件,解压导出的多说评论到同一目录
3.打开start.sql
4.[如果你是在emlog上使用本程序,且数据库前缀为emlog_可忽略这步] 修改第六行,例如评论数据表名称(默认emlog_comment)
5.修改多说文章ID前缀和多说页面ID前缀,如果你是直接写文章ID的话就可以忽略这步了
6.运行start.php,会在本目录下生成output.sql
7.导入到数据库即可
因为之前遇到过此类问题不知如何解决。就当备份。
其实附件里面就是一个 start.php 防止附件失效(博客搬家,有可能损坏),我在这里把代码贴出来,以防万一:
<?php
$dss = json_decode(file_get_contents('export.json'),true);
//前缀,不支持后缀(因为懒)
$threadpf = 'blog-'; //多说文章ID前缀,无前缀留空
$pagepf = 'page-'; //多说页面ID前缀,无前缀留空
$inssql = "INSERT INTO `emlog_comment` (`cid`, `gid`, `pid`, `date`, `poster`, `comment`,`mail`, `url`, `ip`, `hide`) VALUES ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', 'n');\n"; //SQL语句模板
date_default_timezone_set('Asia/Shanghai');
$threadlen = strlen($threadpf);
$pagelen = strlen($pagepf);
$thr = array();
$cids = array();
$result = '';
$tempcid = 0;
foreach ($dss['threads'] as $val1) {
if (strpos($val1['thread_key'], $threadpf) === 0 || strpos($val1['thread_key'], $pagepf) === 0) {
$thr[$val1['thread_id']] = substr($val1['thread_key'] , $threadlen);
}
}
//多说你妹的居然不按父子顺序导出评论
foreach ($dss['posts'] as $val3) {
$tempcid++;
$cids[$val3['post_id']] = $tempcid;
}
foreach ($dss['posts'] as $val2) {
$gid = isset($thr[$val2['thread_id']]) ? $thr[$val2['thread_id']] : '';
if (!empty($gid)) {
if (empty($val2['parent_id'])) {
$pid = '0';
} else {
$pid = isset($cids[$val2['parent_id']]) ? $cids[$val2['parent_id']] : 'FUCKDS';
}
$cid = $cids[$val2['post_id']];
$date = strtotime($val2['created_at']);
$poster = sqladds($val2['author_name']);
$comment = sqladds($val2['message']);
$mail = $val2['author_email'];
$url = sqladds($val2['author_url']);
$ip = $val2['ip'];
$result .= sprintf($inssql, $cid , $gid , $pid , $date , $poster , $comment , $mail , $url , $ip);
}
}
file_put_contents('output.sql', $result);
echo 'Complete! Author: <a href="http://zhizhe8.net/" target="_blank">Kenvix</a> @ <a href="http://www.stus8.com/" target="_blank">StusGame GROUP</a>';
/**
* 使用反斜线引用字符串或数组以便于SQL查询
* 只引用'和\
* @param $s 需要转义的
* @return 转义结果
*/
function sqladds($s) {
if (is_array($s)) {
$r = array();
foreach ($s as $key => $value) {
$k = str_replace('\'','\\\'', str_replace('\\','\\\\',$value));
if (!is_array($value)) {
$r[$k] = str_replace('\'','\\\'', str_replace('\\','\\\\',$value));
} else {
$r[$k] = sqladds($value);
}
}
return $r;
} else {
return str_replace('\'','\\\'', str_replace('\\','\\\\',$s));
}
}
参考:
http://zhizhe8.net/?post=85705
http://www.glr-s.com/em/22.html
http://bbs.emlog.net/thread-40003-1-1.html
让MySQL缺失的ID值自动恢复增长和补全缺失的ID 代码人生
话说,百度知道很强大,自己很弱小呀......才疏学浅.
如下图所示:

想要 cate_id 字段的值 从1开始往下增长 1 2 3 4 5 6 7 8 ....,而不是2 3 4 5 6 7 8 ....
一共有3种修复方法:
第一种手先动修复成1 2 3 4 5 6 7
操作MySQL:输入ALTER TABLE tdb_goods_cates AUTO_INCREMENT = 8
这样往后的资料会从8开始(对于数据量小的可以这么做)
第二种重置表方法
首先--no-create-info,-t仅输出资料
然后把表tdb_goods_cates所有资料使用delete tdb_goods_cates删除
然后输入ALTER TABLE tdb_goods_cates AUTO_INCREMENT = 1
再把输出资料的.sql文件导入就可以了
第三种mysql语法(推荐使用)
UPDATE tdb_goods_cates set cate_id = cate_id-1
然后输入ALTER TABLE tdb_goods_cates AUTO_INCREMENT = 8
这样就可以解决这个问题了.话说,百度知道很强大,自己很弱小呀......才疏学浅.
MySQL学习之多表更新一步到位 代码人生
首先说明:个人学习笔记而已,不喜勿看,以免不适.
mysql> CREATE TABLE IF NOT EXISTS tdb_goods_cates(
-> cate_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
-> cate_name VARCHAR(40) NOT NULL)
-> default charset=utf8
-> ;
Query OK, 0 rows affected (0.02 sec)
mysql> set NAMES gbk;
Query OK, 0 rows affected (0.00 sec)
在要创建的表后加 DEFAULT CHARSET=utf8; 防止中文乱码
链接类型
INNER JOIN 内连接
JOIN, CROSS JOIN, INNER JOIN 是等价的
RIGHT [OUTER] JOIN 右外链接
连接条件:
使用 ON 关键字来设定连接条件,也可以使用 WHERE 来代替。
通常使用 ON 关键字来设定连接条件
使用 WHERE 关键字进行结果集记录的过滤
内连接:返回左表及右表符合连接条件的记录(即两表的交集部分)

UPDATE table_references SET col_name1={express|DEFAULT} [,col_name2={expr2|DEFAULT}]...[WHERE where_condition]
语法结构
table_reference
{[INNER|CROSS]JOIN|{LEFT|RIGHT}[OUTER]JOIN}
Ttable_reference
ON condition_expr
外连接:
以左外连接为例:
A LEFT JOIN B join_condition
数据表B的结果集依赖于数据表A
数据表A的结果集根据左连接条件依赖所有数据表(B表除外)
左外连接条件决定如何检索数据表B(在没有指定WHERE条件的情况下)
如果数据表A的某条记录符合WHERE条件,但是在数据表B不存在符合连接条件的记录,将生成一个所有列为空的额外的B行
内连接:
使用内连接查找的记录在连接数据表中不存在,并且在WHERE子句中尝试一下操作:column_name IS NULL 。如果 column_name 被指定为 NOT NULL,MySQL将在找到符合连接着条件的记录后停止搜索更多的行(查找冲突)
mysql> UPDATE tdb_goods INNER JOIN tdb_goods_cates ON goods_cate=cate_name
-> SET goods_cate=cate_id;
Query OK, 22 rows affected (0.01 sec)
Rows matched: 22 Changed: 22 Warnings: 0
mysql> CREATE TABLE IF NOT EXISTS tdb_goods_brands(
musqlbrand_id SMALLINT PRIMARY KEY AUTO_INCREMENT,
brand_name VARCHAR(40) NOT NUL)
DEFAULT CHARSET=UTF8
SELECT brand_name FROM tdb_goods GROUP BY brand_name;
多表更新 一步到位 在创建表的时候就将选择(select)插入(insert)一起搞定
mysql> UPDATE tdb_goods INNER JOIN tdb_goods_brands ON brand_name = brand_name
SET brand_name = brand_id;
这样将会出现错误 因为MySQL不能分清brand_name所指的是哪一个表的字段,因此 需要设置别名或者是字段前面加上表明
mysql> UPDATE tdb_goods AS A INNER JOIN tdb_goods_brands AS B ON A.brand_name =
B.brand_name SET A.brand_name = B.brand_id;
一般情况下使用别名 比较方便.
但是
| goods_cate | varchar(40)
| brand_name | varchar(40)
最好做如下修改
mysql> ALTER TABLE tdb_goods
-> CHANGE goods_cate cate_id SMALLINT UNSIGNED NOT NULL,
-> CHANGE brand_name brand_id SMALLINT UNSIGNED NOT NULL;
Query OK, 23 rows affected, 1 warning (0.06 sec)
Records: 23 Duplicates: 0 Warnings: 1
使用ALTER TABLE 修改指定表的字段或者字段的值
-
admin 约 20 小时前
@東咩:无
-
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
哥,还能再分享不 百度账号:東咩
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。
-
admin 2024-03-28 22:38
@人大代表:卧槽 别搞我...
-
24年的新闻,你22年爆出来了。厉害了,大哥。

