FileOptimizer-利用谷歌开源的图片算法Guetzli优化你的图片 神器荟萃
先做个简单的介绍,估计很多人不知道这个软件:
FileOptimizer是一种高级文件优化器,具有无损(无质量损失)文件大小压缩功能,可支持的文件类型有:
.3GP, .A, .AAI, .AC, .ACC, .ADP, .AI, .AIR, .APK, .APNG, .APPX, .APR, .ART, .AVS, .BAR, .BMP, .BPL, .BSZ, .CBT, .CBZ, .CDR, .CDT, .CHI, .CHM, .CHQ, .CHS, .CHW, .CPL, .CSL, .CSS, .DB, .DCX, .DEB, .DES, .DIB, .DLL, .DOC, .DOCM, .DOCX, .DOT, .DOTM, .DOTX, .DRV, .DWF, .DWFX, .EASM, .EML, .EMLX, .EPDF, .EPRT, .EPUB, .EXE, .FAX, .FB2, .FDF, .FITS, .FLA, .FLAC, .FPX, .FXG, .GALLERY, .GALLERYCOLLECTION, .GALLERYITEM, .GIF, .GRS, .GZ, .HDR, .HRZ, .HTM, .HTML, .ICO, .INK, .IPA, .IPK, .IPSW, .ITA, .ITS, .ITZ, .JAR, .JFI, .JFIF, .JIF, .JNG, .JP2, .JPC, .JPE, .JPEG, .JPG, .JPS, .JS, .JSON, .KML, .KMZ, .KSF, .LIB, .LIT, .LUA, .LUAC, .LXF, .LZL, .M4A, .M4B, .M4P, .M4R, .M4V, .MAX, .MBX, .MCE, .MDB, .MDT, .MDZ, .MHT, .MHTML, .MIC, .MIF, .MIFF, .MIX, .MIZ, .MKA, .MKS, .MKV, .MMIP, .MNG, .MP3, .MP4, .MPD, .MPO, .MPP, .MPT, .MSC, .MSG, .MSI, .MSP, .MST, .MSZ, .MTV, .MTW, .MVZ, .NAR, .NBK, .NOTEBOOK, .O, .OBJ, .OCX, .ODB, .ODF, .ODG, .ODP, .ODS, .ODT, .OEX, .OGA, .OGG, .OGV, .OGX, .OLE, .OLE2, .ONE, .OPT, .OSK, .OST, .OTB, .OXPS, .P7, .PALM, .PBM, .PCC, .PCD, .PCDS, .PCX, .PDB, .PDF, .PFM, .PGM, .PIC, .PICON, .PICT, .PK3, .PNG, .PNM, .PNS, .POTM, .POTX, .PPAM, .PPM, .PPS, .PPSM, .PPSX, .PPT, .PPTM, .PPTX, .PSB, .PSD, .PTIF, .PTIFF, .PUB, .PUZ, .R2SKIN, .RDB, .RFA, .RFT, .RMSKIN, .RTE, .RVT, .S3Z, .SCR, .SGML, .SLDASM, .SLDDRW, .SLDM, .SLDPRT, .SLDX, .SOU, .SPL, .SPO, .STZ, .SUN, .SVG, .SVGZ, .SWC, .SWF, .SYS, .TAR, .TGZ, .THM, .TIF, .TIFF, .VBX, .VCARD, .VCF, .VDX, .VICAR, .VIFF, .VLT, .VSD, .VSS, .VST, .VSX, .VTX, .WAL, .WBA, .WBMP, .WEBP, .WIZ, .WMZ, .WPS, .WSZ, .XAP, .XBM, .XHTML, .XL, .XLA, .XLAM, .XLC, .XLM, .XLS, .XLSM, .XLSX, .XLTM, .XLTX, .XLW, .XML, .XMZ, .XNK, .XPI, .XPM, .XPS, .XSF, .XSL, .XSLT, .XSN, .XWD, .ZIP, STICKYNOTES.SNT, and THUMBS.DB 等格式.
2017年3月16日谷歌新开源了一个图片压缩优化算法Guetzli。这是谷歌官方的博客
FileOptimizer是一个通用文件优化器,它是Guetzli支持的程序之一。
官方网站: http://nikkhokkho.sourceforge.net/static.php?page=FileOptimizer
当然在sourceforge.net也可以下载的: https://sourceforge.net/projects/nikkhokkho/files/FileOptimizer/
下面我就说一下我的使用体会和我觉得大家应该注意的地方:
- 软件分为两中形式的,一个是安装包的gui界面,一个是压缩包形式,直接解压缩修改配置文件就可以使用.
- 第一是安装包的下载地址:链接: https://pan.baidu.com/s/1kV1Dtbx 密码: mrxn
- 压缩包形式的下载地址:链接:https://pan.baidu.com/s/1crMsiE 密码:mrxn
- 不管是安装版的还是压缩包形式的,都要设置才能使用最新的图片压缩算法Guetzli.怎么设置我在下面会讲.
我自己使用的是安装版的,我就讲一下安装版的,压缩包的网上有人已经写了,我就不在重复,我会给出链接的.
当我们安装好之后,打开软件,在菜单栏依次找到Optimize--Options. 然后在弹出的对话框按照我的图片设置就行:
第一个界面的 Do not use recycle bin .意思就是说是否需要保留源文件到回收站中,默认是保留的,你优化完文件觉得不好,想找回源文件就去回收站恢复就行了.当然,在回收站里面是会占用你得内存的,所以如果你觉得没必要保留就把复选框选上,之后优化文件就不会保留源文件到回收站了.

第二个就是在png那个图片那里设置把 Allow lossy optimizations 复选框勾上,默认是没有勾上的.还有就是JPEG的Use arithmetic encoding的复选框勾上.下面把工作界面说一下,看图(新窗口查看高清大图):

下面看我的对比测试,我把我的博客的所有上传文件夹使用zip打包后,大小为136M,我使用FileOptimizer压缩后,大小变为74M,减小了54%.总体的减小不但节约了服务器空间成本,更重要的是每个单个的图片的体积减小可以加快网页的加载速度,提升用户体验.这对站长来说还是比较开心的吧!


而且,他不支持的文件格式他会自动跳过,你不用担心.
说了这么多的优点,来说说他的缺点:
就是处理速度慢,一张1M左右的图片处理会要两三分钟,但是平时的网站图片来说,200-300Kb的需要5-6秒.如果图片比较多,建议网上挂机处理或者是放在远程服务器上挂机处理.但是重要的是:
实测对质量在90或以下的jpg图片,guetzli输出的新图质量不会降低。而实际压缩率能够达到平均压缩率29%。
兼容性比较好,输出的jpeg格式图片通用性非常高。没有webp、sharpp那种协议不兼容的困扰。
在客户端jpeg格式的图片编解码速度比其他私有协议快很多。
下面说一下压缩包的使用方法:
Guetzli不是默认的解码器,因为它并不是无损的,所以要在FileOptimizer中启用Guetzli支持。所以你需要执行以下步骤:
- 在安装路径下打开FileOptimizer[你安装的位数].ini
小编的是
D:\FileOptimizer\FileOptimizer64.ini
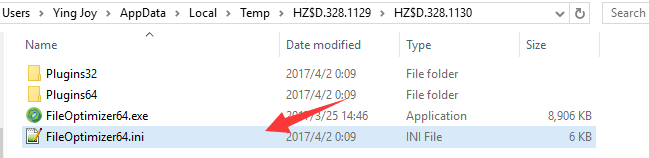
2.找到JPEGAllowLossy参数,并将其设置为true。
在26行(Notepad++打开)
3.重启FileOptimizer软件
优化你的图片
小编随便使用了几张图片
最后看见优化效果还是不错的

利用d3.js对大数据资料进行可视化分析 网络安全
作者: Anthr@X [email protected]
0x00 背景
对于前段时间流出的QQ群数据大家想必已经有所了解了,处理后大小将近100G,多达15亿条关系数据(QQ号,群内昵称,群号,群内权限,群内性别和年龄)和将近9000万条群信息(群号,群名,创建时间,群介绍),这些数据都是扁平化的2维表格结构,直接查询不能直接体现出用户和群之间的直接或者间接关系。通过数据可视化,可以把扁平结构的数据作为点和线连接起来,从而更加直观的显示出来从而进行分析。
d3.js是一个近年来推出的基于javascript的数据展示库,全称为Data Driven Document, 在浏览器数据展示领域的地位类似于通用js框架里的jQuery。d3.js的官网是d3js.org,大家可以在上面看到很多例子和应用。d3.js也是图形数据库neo4j所内置的数据展示工具。
说到图形数据库,其实正确的翻译应该是图数据库,图即所谓的Graph,来自于数学里的图论,比如四色定理和推销员过桥的问题(著名的NP问题之一)。图数据库着重于数据之间的关联和属性,对于关系错综复杂的关系分析效率很高。例如,我想知道谁是我朋友的朋友,并且他们有哪些朋友也认识我。对于这种问题,普通关系型数据库的计算复杂度是O(N^c)左右或者更高,N为选择范围的数据集合大小,你好友数量加上好友的好友的数量等,c为关系层数。图数据库的计算复杂度在O(N^2)左右或者更低,但是基本不会超过O(N^2)。图数据库对于复杂关系数据查询起来效率高的主要原因是在数据输入的时候就已经对关系进行了处理和索引,这样做在查询的时候具有很高的效率,但是在数据导入的时候会很慢。QQ群的15亿个关系在向图数据库neo4j里导入的时候花了3天都没弄完,也没有进度提示,所以后来我直接放弃了。
0x01 数据处理
在QQ群和群成员关系里面,对于层数我是这么定义的:
第1层:目标QQ加入的所有群 第2层:目标QQ加入的所有群的所有成员 第3层:目标QQ加入的所有群的所有成员加入的所有群 . . .
大家可以看出这样的查询是可以递归的,假设每个QQ号所加入的群数量和每个群的成员数量为N,那么查询3层数据时总计算量为N*N*N=n^3,所以当查询层数为c层的时候,计算复杂度是N^c。
前面说过,图数据库的计算复杂度一般在N^2以下,所以当使用普通的关系型数据库的时候,如果查询的层数不多,效率和图数据库比起来差不多,加上关系数据库自带的便于管理和导入导出的属性,所以我还是选择了mysql数据库。
对于QQ和QQ群之间的关系,每个QQ号都能加入群,一个群里也有很多QQ,基本都在几十到几百人,所以两个QQ号在同一个群里不一定代表他们的关系很紧密,换句话说QQ和QQ群之间的关系相对于QQ好友而言相对较弱。但是这并不代表我们从中不能分析出有用的资料,俗话说的好,大数据就像一座金矿,只有用力挖才能挖到金子。
d3.js支持多种数据格式,比如JSON,XML,CSV,HTML等,因为PHP的数组可以很简单的转换为JSON格式,所以我选择用PHP写API来获取JSON数据。QQ和QQ群是一种典型的图数据的应用,QQ和QQ群作为节点(node),QQ加入了哪些群作为关系(link),d3.js内置了一个功能很强大的内建布局,叫做Force-Directed Graph(受力导向图),后面简称为force。force布局模拟了一些基本的物理粒子原理,比如引力和斥力(确切的说是模拟了电磁力和引力,在离的远的时候会互相吸引,在离的近的时候斥力急剧增加),并且可以调节力的大小和受力距离等等,可以说是自由度相当高。关于d3.js的force布局,在官网有详细的API和不少例子,这里我就不贴代码了。
在force布局里面,数据源的JSON可以有很多种不同的格式和属性,但是基本格式如下:
{"nodes":[{"num":10001,type:"qq"},{"num":12345678,type:"qun"}],"links":[{"source":"10001","target":"12345678","auth":1,"nick":"pony"}]}
其中nodes数组对应的是节点列表,links对应的是关系列表。
每个节点可以有很多自定义属性,在d3.js可以针对每个节点存取节点的属性,比如我定义num是QQ号或者群号,type代表节点是QQ还是群,另外我在js里设定在type==‘qun’的时候显示群的图标,是qq的时候显示qq的图标。关系里面默认的属性有source和target,分别对应一个关系的两头,默认情况下关系里面的source和target对应的数字是节点在节点数组里面的位置index。但是我自定义成了qq号和群号。另外你也可以定义其他属性,比如auth代表这个QQ号在群里的权限,nick是群昵称。
对于QQ群这样的关系来说,基本上在第4层和以上的QQ和群的关系就比较弱了,所以为了提高查询速度和减少节点数量,我只查询2层关系(少么?不少,要想想有些群有超过500人……)。
首先,d3.js需要在浏览器里面运行,我的首选是Google Chrome,V8引擎的效率果然不错,在节点和关系不多的时候基本感觉不到延迟,后来在FF和IE11里面测试了一次,FF比Chrome卡一半左右,IE的话我只能呵呵了……
先拿小马哥做个测试,QQ号是霸气的10001。当d3.js导入完数据JSON的时候,各种节点会在屏幕上乱飞几秒钟,直到他们的力达到一个稳定的平衡点。结果如下:
说明:
企鹅图标的节点代表QQ,群图标的节点是群(废话么)。 每条线代表一个关系,一个QQ可以加入N个群,一个群也可以有N个QQ加入。 线的颜色分别代表: 土豪金:群主 狗腿绿:群管理员 屌丝蓝:群成员
大家也可以看到,群主和管理员的关系线也比普通的群成员长一些,这是为了突出群内的重要成员的关系。
图标旁边自动标注了QQ号和群号,如果有的话还有群名。没有在QQ号旁边标注昵称是因为很多人加入不同的群使用的是不同昵称,所以把昵称放到了其他的地方显示。
在下图中大家可以隐约的看到,所有的关系都是以QQ 10001为起点的。

在图上节点是可以拖拽的,拖拽后会固定在你释放的地方。我们把几个群稍微拖的分开一点,关系就一目了然了
这个时候我们可以看到在目标的QQ群里也有很多共同QQ号,比如有些QQ号同时加入了2,3个群。群名显示的都是各种产品开发讨论群,这些同时加入2,3个产品群的人估计不是产品经理就是主管吧……

鼠标悬停到群图标上可以看到群的详细信息(如果有的话)

因为很多人在不同群里的昵称不一样,所以群内昵称等信息就只能放到link上面了,因为线比较细,所以鼠标比较难对准,这个功能还待修改。
这个家伙和小马哥一起同时在3个群里,好基友?

小马哥的QQ群信息展示完了,下面我们来看看更加实际的应用,比如把某圈子里的人找出来。我们先从某土豪大黑阔大牛的QQ号入手:
初始数据好多……此大黑阔加入的群够杂的,不过就是因为杂所以才能更深入的了解一个人的所有喜好。看看群名神马的,我好像看到了dota,XX国际俱乐部,web技术交流,XXsec等群……充分说明了此人……是个屌丝技术宅大黑阔,XX国际俱乐部又似乎带着那么种高大上的感觉……
图中错综复杂的各种关系组成了一朵朵盛开的菊花,向我们诉说着他的历史……

为了理清他那不堪回首的过去和关系网,我特地把浏览器窗口拖到第二个屏幕上,然后把群挨个分开。为了保护当事人的隐私,这张图我打码了。
这张图比较宽,建议大家下载下来放大看

0x02 总结
假如把层数扩展到4层,不知能否筛选出中国所有黑阔的QQ号呢?至少我已经在这张图里看到了很多熟悉的名字和号码。
腾讯总是说漏洞早已修复,不存在问题了,广大网民放心,但实际上信息泄露这种事情,岂是你漏洞修复好了就结束了的事情?
注:转载自乌云文库,原作者为QQ群关系查询站的站长 --- insight-labs ,原文地址:http://drops.wooyun.org/tips/823
Linux VPS/服务器上用Crontab定时执行脚本/命令来实现VPS自动化 Linux
VPS或者服务器上经常会需要VPS或者服务器上经常会需要定时备份数据、定时执行重启某个服务或定时执行某个程序等等,一般在Linux使用Crontab,Windows下面是用计划任务(Win的都是图形界面设置比较简单),下面主要介绍Linux VPS/服务器上Crontab的安装及使用。
Crontab是一个Unix/Linux系统下的常用的定时执行工具,可以在无需人工干预的情况下运行指定作业。
一、Crontab的安装
1、CentOS下面安装Crontab
yum install vixie-cron crontabs //安装Crontab chkconfig crond on //设为开机自启动 service crond start //启动
说明:vixie-cron软件包是cron的主程序;crontabs软件包是用来安装、卸装、 或列举用来驱动 cron 守护进程的表格的程序。
2、Debian下面安装Crontab
apt-get install cron //大部分情况下Debian都已安装。 /etc/init.d/cron restart //重启Crontab
二、Crontab使用方法 1、查看crontab定时执行任务列表
crontab -l
2、添加crontab定时执行任务
crontab -e

输入crontab任务命令时可能会因为crontab默认编辑器的不同。
如上图所示为nano编辑器,使用比较简单,直接在文件末尾按crontab命令格式输入即可,Ctrl+x退出,再输y 回车保存。
另外一种是vi编辑器,首先按i键,在文件末尾按crontab命令格式输入,再按ESC键,再输入:wq 回车即可。
3、crontab 任务命令书写格式
| 格式: | minute | hour | dayofmonth | month | dayofweek | command |
| 解释: | 分钟 | 小时 | 日期 | 月付 | 周 | 命令 |
| 范围: | 0-59 | 0~23 | 1~31 | 1~12 |
0~7,0和7都代表周日 |
在crontab中我们会经常用到* , - /n 这4个符号,好吧还是再画个表格,更清楚些:

下面举一些例子来加深理解:
每天凌晨3:00执行备份程序:0 3 * * * /root/backup.sh
每周日8点30分执行日志清理程序:30 8 * * 7 /root/clear.sh
每周1周5 0点整执行test程序:0 0 * * 1,5 test
每年的5月12日14点执行wenchuan程序:0 14 12 5 * /root/wenchuan
每晚18点到23点每15分钟重启一次php-fpm:*/15 18-23 * * * /etc/init.d/php-fpm
其他一些命令:
/sbin/service crond start //启动服务 /sbin/service crond stop //关闭服务 /sbin/service crond restart //重启服务 /sbin/service crond reload //重新载入配置 service crond status //查看crontab服务状态 service crond start //手动启动crontab服务
4,设置定时任务:【语 法:crontab [-u <用户名称>][配置文件] 或crontab [-u <用户名称>][-elr]】
5,参 数:
-e 编辑该用户的计时器设置。
-l 列出该用户的计时器设置。
-r 删除该用户的计时器设置。
-u<用户名称> 指定要设定计时器的用户名称。
6,格式:分 时 日 月 周 命令
7,列举,比如我要每天的23点50重启nginx服务,那么,我就输入如下命令:
crontab -e
然后打开一个编辑窗口,按下 insert 按键或者是i,输入:
50 23 * * * /etc/init.d/nginx restart
1,crontab命令
功能说明:设置计时器。
语 法:crontab [-u <用户名称>][配置文件] 或 crontab [-u <用户名称>][-elr]
补充说明:cron是一个常驻服务,它提供计时器的功能,让用户在特定的时间得以执行预设的指令或程序。只要用户会编辑计时器的配置文件,就可以使 用计时器的功能。其配置文件格式如下:
Minute Hour Day Month DayOFWeek Command
参 数:
-e 编辑该用户的计时器设置。
-l 列出该用户的计时器设置。
-r 删除该用户的计时器设置。
-u<用户名称> 指定要设定计时器的用户名称。
2,crontab 格式
基本格式 :
* * * * * command
分 时 日 月 周 命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列 表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
# Use the hash sign to prefix a comment
# +—————- minute (0 – 59)
# | +————- hour (0 – 23)
# | | +———- day of month (1 – 31)
# | | | +——- month (1 – 12)
# | | | | +—- day of week (0 – 7) (Sunday=0 or 7)
# | | | | |
# * * * * * command to be executed
crontab文件的一些例子:
30 21 * * * /etc/init.d/nginx restart
每晚的21:30重启 nginx。
45 4 1,10,22 * * /etc/init.d/nginx restart
每月1、 10、22日的4 : 45重启nginx。
10 1 * * 6,0 /etc/init.d/nginx restart
每周六、周日的1 : 10重启nginx。
0,30 18-23 * * * /etc/init.d/nginx restart
每天18 : 00至23 : 00之间每隔30分钟重启nginx。
0 23 * * 6 /etc/init.d/nginx restart
每星期六的11 : 00 pm重启nginx。
* */1 * * * /etc/init.d/nginx restart
每一小时重启nginx
* 23-7/1 * * * /etc/init.d/nginx restart
晚上11点到早上7点之间,每 隔一小时重启nginx
0 11 4 * mon-wed /etc/init.d/nginx restart
每月的4号与每周一到周三 的11点重启nginx
0 4 1 jan * /etc/init.d/nginx restart
一月一号的4点重启nginx
*/30 * * * * /usr/sbin/ntpdate 210.72.145.20
每半小时同步一下时间
如果需要根据centos vps内存大小来判断然后重启,看以参考这篇文章:
Linux脚本:根据CPU负载及内存使用率自动重启服务进程
20个免费的网站测试工具 代码人生
前言:做前端开发的,网页加载速度和用户体验很重要。所以,今天搜集了这些测试网页速度的专业网站工具,博主推荐google的Googlespeed,很全面。
本文将介绍20个网站速度的测试工具。网页性能很大程度上决定了用户体验,最终可以决定网站的成功。虽然我们都知道提高浏览速度的重要性,可是很多时候我 们不知道什么元素拖了后腿。这里将介绍的工具可以帮助你确定网页上的速度瓶颈,从而能够让你找到问题,进而解决问题,设计出高效的网站。
Google的Page Speed Online(页面在线速度)启用了Google的网页性能优化方案。输入你的网站,跑网页分析。结束之后,Page Speed会打出一个综合分数,让后提供一套该净方案的总结报告:你可以逐个点击查看。它还包括了手机端的网速测试。

2. Pingdom Tools

Pingdom提供服务器,网络和网页监测。它的总结报告更加详细:网页上的每一个对象的速度都有一份独立报告(图像、视屏、脚本、样式表等),其中还包括了网页缓存。报告中的细目包括了下载速度,网页大小和提交的协议
3. Free Website Performance Test (BrowserMob)
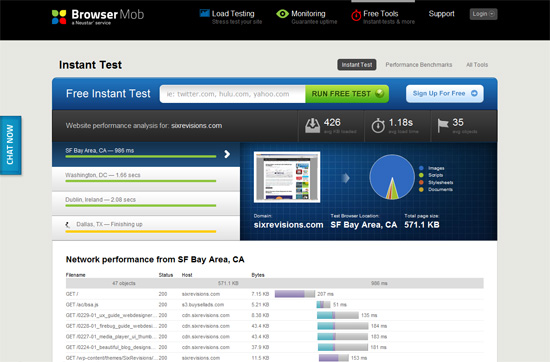
BrowserMob的产品,提供网页加载测试和监测服务。它的报告信息量更大(如图)。还有一个特点是,它从全球4个地方ping你的网站,让后给出综合报告。给了你一个全球性的视角。
4. Which loads faster?
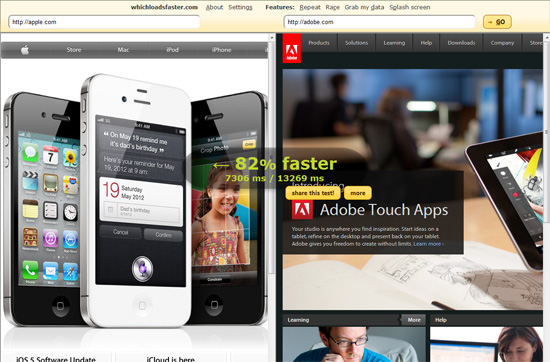
这个工具比较两个网站的速度,最后提供的报道是个相对的信息。这样的工具很有用处:譬如输入google 和bing 来比较两者的优劣。同样的,你可以用它来比较自己和竞争者的网站。值得一提的是,它是个开源的工具。
5. WebPagetest
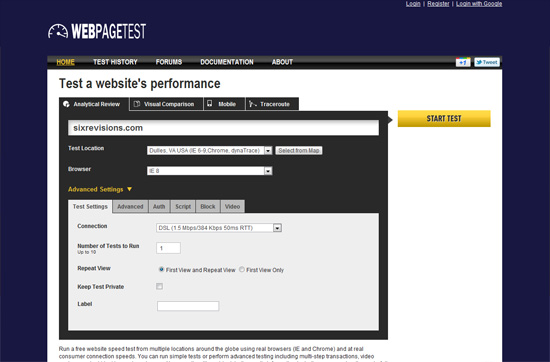
这个小巧的工具是把你的网页加载到浏览器上从而测试他们的网页加载速度(浏览器包括了Chrome,Firefox 和IE).用户还能选择全球不同的地点打开你的网页的速度。更加高级的功能是你能选择用户端网速和是否包括“屏蔽广告”,你就能知道在网页上跑广告的性能 代价
6. Web Page Analyzer
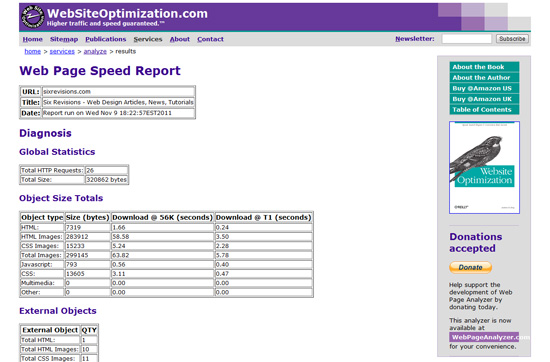
这是所有这些性能测试里面最老的一个,建于2003年;根据测试报告,附加提供性能的意见。
7. Show Slow
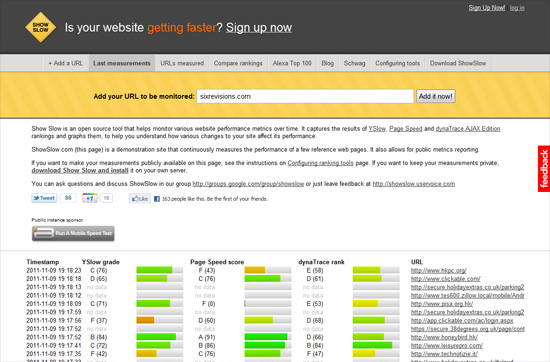
服务器应用ShowSlow的开源网页版;你可以添加需要检测的网页,show slow帮你用三大测试工具(YSlow,PageSpeed 和dynaTrac)定时测试。这个工具虽然是免费的,但是需要注册使用。
8. Site-Perf
这个对于网页设计人员来讲,有点太技术性,它的数据报告是基于发送包的数量和经过的路由器等等数据结合的;没有针对网页设计人员的总结。但是对于技术人员来讲,又简单了点。但是它有一个特点,对于需要登录的网页,提供用户名和密码也能监测。
9. Load Impact
这个是20个工具里面功能最强大的。它可以进行压力测试:用虚拟器模拟用户,观测随着用户增加,网页性能的变化。可以测试出你的网页的耐用和高效。
10. OctaGate SiteTimer
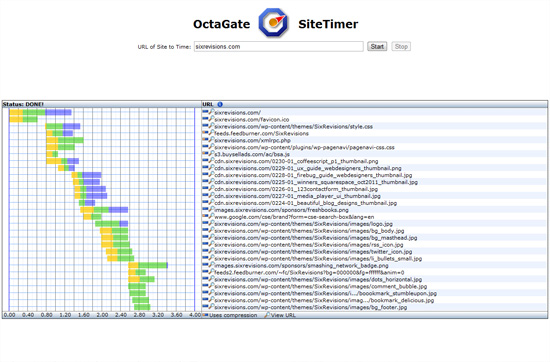
这个是所有工具里面最直观的;如果你就想知道你的网页里面哪个元素拖了后腿,就跑这个工具。它就一张图,告诉你每个网页元素下载需要时间。
另外10个:
- Web Site Performance Test (Gomez) – 实时检测,深入到包括了查找域名时间。
- Webslug – 比较两个网站从而给出一个相对性能优劣总结
- WebWait – 简单的工具;你给出要多少次要求,它显示每次要网页间的时间差
- Website Speed Test (Searchmetrics) – 基于网络速度,给出网页性能报表。
- GTmetrix – 用Yslow和PageSpeed做测试的工具网站。总结报告一目了然,适用于对外报告。
- Website Speed Test (WebToolHub) – 表格形式,可以用在商务企划书上。
- Yottaa Site Speed Optimizer – 需要注册。可以用在商业企划书上,总结报告做地很漂亮。
- Zoompf Free Web Performance Scan – 需要电邮注册。它会扫一下你的网页,总结出取决网页性能的元素。
- Site speed checker – 可以定义测试,然后放在最多10个网页上一起跑。
- Free web site speed test (Self SEO) – 可以10个网页一起测试,看它们之间的差别。
CentOS下安装netspeeder加速 技术文章
1、作者项目主页,https://code.google.com/p/net-speeder/
已经迁移到github了:https://github.com/snooda/net-speeder (作者主页也有教程)
安装步骤如下:
安装脚本
获得安装包: wget http://linux.linzhihao.cn/shell/netspeeder.sh
运行安装包:sh netspeeder.sh
然后再看看进程,如果能找到net_speeder ,说明它正在运行,安装就成功了
使用方法(需要root权限启动):
参数:./net_speeder 网卡名 加速规则(bpf规则)
最简单用法: # ./net_speeder venet0 "ip" 加速所有ip协议数据
关闭net_speeder方法:killall net_speeder
2、net-speeder是一个由snooda.com博主写的Linux脚本程序,主要目的是为了解决丢包问题,实现TCP双倍发送,即同一份数据包发送两份。这样的话在服务器带宽充足情况下,丢包率会平方级降低。
3、net-speeder对于不加速就可以跑满带宽的类型来讲(多线程下载),开启后反而由于多出来的无效流量,导致速度减半,性能开销稍大和自由度有损失。所以,如果你的VPS连接国内速度一切正常,请不要启用net-speeder。
4、安装net-speeder的方法也很简单,这里提供由lazyzhu.com博主写的net-speeder一键安装包。执行以下命令:
wget --no-check-certificate https://gist.github.com/LazyZhu/dc3f2f84c336a08fd6a5/raw/d8aa4bcf955409e28a262ccf52921a65fe49da99/net_speeder_lazyinstall.sh
sh net_speeder_lazyinstall.sh

5、日后如果一键安装脚本下载链接失效了,这里给出脚本的具体内容,大家可以将将它保存为.sh文件,然后就可以执行了。
#!/bin/sh
# Set Linux PATH Environment Variables
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
export PATH
# Check If You Are Root
if [ $(id -u) != "0" ]; then
clear
echo -e "\033[31m Error: You must be root to run this script! \033[0m"
exit 1
fi
if [ $(arch) == x86_64 ]; then
OSB=x86_64
elif [ $(arch) == i686 ]; then
OSB=i386
else
echo "\033[31m Error: Unable to Determine OS Bit. \033[0m"
exit 1
fi
if egrep -q "5.*" /etc/issue; then
OST=5
wget http://dl.fedoraproject.org/pub/epel/5/${OSB}/epel-release-5-4.noarch.rpm
elif egrep -q "6.*" /etc/issue; then
OST=6
wget http://dl.fedoraproject.org/pub/epel/6/${OSB}/epel-release-6-8.noarch.rpm
else
echo "\033[31m Error: Unable to Determine OS Version. \033[0m"
exit 1
fi
rpm -Uvh epel-release*rpm
yum install -y libnet libnet-devel libpcap libpcap-devel gcc
wget http://net-speeder.googlecode.com/files/net_speeder-v0.1.tar.gz -O -|tar xz
cd net_speeder
if [ -f /proc/user_beancounters ] || [ -d /proc/bc ]; then
sh build.sh -DCOOKED
INTERFACE=venet0
else
sh build.sh
INTERFACE=eth0
fi
NS_PATH=/usr/local/net_speeder
mkdir -p $NS_PATH
cp -Rf net_speeder $NS_PATH
echo -e "\033[36m net_speeder installed. \033[0m"
echo -e "\033[36m Usage: nohup ${NS_PATH}/net_speeder $INTERFACE \"ip\" >/dev/null 2>&1 & \033[0m"
5、安装完成后,会给出脚本用法,最简单的就是开启所有IP协议加速。执行以下命令:
nohup /usr/local/net_speeder/net_speeder venet0 "ip" >/dev/null 2>&1 &
6、net-speeder对于VPS速度有没有优化?就我自己的测试来看,速度和ping值都有所提升,但是流量也是双倍呀!所以对于流量吃紧的童鞋们来说,就别尝试了。。。当然,流量多的就无视。
设置Sysctl.conf用以提高Linux的性能(最完整的sysctl.conf优化方案) 技术文章
Sysctl是一个允许您改变正在运行中的Linux系统的接口。它包含一些 TCP/IP 堆栈和虚拟内存系统的高级选项, 这可以让有经验的管理员提高引人注目的系统性能。用sysctl可以读取设置超过五百个系统变量。基于这点,sysctl(8) 提供两个功能:读取和修改系统设置。
查看所有可读变量:
% sysctl -a
读一个指定的变量,例如 kern.maxproc:
% sysctl kern.maxproc kern.maxproc: 1044
要设置一个指定的变量,直接用 variable=value 这样的语法:
# sysctl kern.maxfiles=5000
kern.maxfiles: 2088 -> 5000
您可以使用sysctl修改系统变量,也可以通过编辑sysctl.conf文件来修改系统变量。sysctl.conf 看起来很像 rc.conf。它用 variable=value 的形式来设定值。指定的值在系统进入多用户模式之后被设定。并不是所有的变量都可以在这个模式下设定。
sysctl 变量的设置通常是字符串、数字或者布尔型。 (布尔型用 1 来表示’yes’,用 0 来表示’no’)。
sysctl -w kernel.sysrq=0
sysctl -w kernel.core_uses_pid=1
sysctl -w net.ipv4.conf.default.accept_redirects=0
sysctl -w net.ipv4.conf.default.accept_source_route=0
sysctl -w net.ipv4.conf.default.rp_filter=1
sysctl -w net.ipv4.tcp_syncookies=1
sysctl -w net.ipv4.tcp_max_syn_backlog=2048
sysctl -w net.ipv4.tcp_fin_timeout=30
sysctl -w net.ipv4.tcp_synack_retries=2
sysctl -w net.ipv4.tcp_keepalive_time=3600
sysctl -w net.ipv4.tcp_window_scaling=1
sysctl -w net.ipv4.tcp_sack=1
配置sysctl
编辑此文件:
vi /etc/sysctl.conf
如果该文件为空,则输入以下内容,否则请根据情况自己做调整:
# Controls source route verification # Default should work for all interfaces net.ipv4.conf.default.rp_filter = 1 # net.ipv4.conf.all.rp_filter = 1 # net.ipv4.conf.lo.rp_filter = 1 # net.ipv4.conf.eth0.rp_filter = 1 # Disables IP source routing # Default should work for all interfaces net.ipv4.conf.default.accept_source_route = 0 # net.ipv4.conf.all.accept_source_route = 0 # net.ipv4.conf.lo.accept_source_route = 0 # net.ipv4.conf.eth0.accept_source_route = 0 # Controls the System Request debugging functionality of the kernel kernel.sysrq = 0 # Controls whether core dumps will append the PID to the core filename. # Useful for debugging multi-threaded applications. kernel.core_uses_pid = 1 # Increase maximum amount of memory allocated to shm # Only uncomment if needed! # kernel.shmmax = 67108864 # Disable ICMP Redirect Acceptance # Default should work for all interfaces net.ipv4.conf.default.accept_redirects = 0 # net.ipv4.conf.all.accept_redirects = 0 # net.ipv4.conf.lo.accept_redirects = 0 # net.ipv4.conf.eth0.accept_redirects = 0 # Enable Log Spoofed Packets, Source Routed Packets, Redirect Packets # Default should work for all interfaces net.ipv4.conf.default.log_martians = 1 # net.ipv4.conf.all.log_martians = 1 # net.ipv4.conf.lo.log_martians = 1 # net.ipv4.conf.eth0.log_martians = 1 # Decrease the time default value for tcp_fin_timeout connection net.ipv4.tcp_fin_timeout = 25 # Decrease the time default value for tcp_keepalive_time connection net.ipv4.tcp_keepalive_time = 1200 # Turn on the tcp_window_scaling net.ipv4.tcp_window_scaling = 1 # Turn on the tcp_sack net.ipv4.tcp_sack = 1 # tcp_fack should be on because of sack net.ipv4.tcp_fack = 1 # Turn on the tcp_timestamps net.ipv4.tcp_timestamps = 1 # Enable TCP SYN Cookie Protection net.ipv4.tcp_syncookies = 1 # Enable ignoring broadcasts request net.ipv4.icmp_echo_ignore_broadcasts = 1 # Enable bad error message Protection net.ipv4.icmp_ignore_bogus_error_responses = 1 # Make more local ports available # net.ipv4.ip_local_port_range = 1024 65000 # Set TCP Re-Ordering value in kernel to ‘5′ net.ipv4.tcp_reordering = 5 # Lower syn retry rates net.ipv4.tcp_synack_retries = 2 net.ipv4.tcp_syn_retries = 3 # Set Max SYN Backlog to ‘2048′ net.ipv4.tcp_max_syn_backlog = 2048 # Various Settings net.core.netdev_max_backlog = 1024 # Increase the maximum number of skb-heads to be cached net.core.hot_list_length = 256 # Increase the tcp-time-wait buckets pool size net.ipv4.tcp_max_tw_buckets = 360000 # This will increase the amount of memory available for socket input/output queues net.core.rmem_default = 65535 net.core.rmem_max = 8388608 net.ipv4.tcp_rmem = 4096 87380 8388608 net.core.wmem_default = 65535 net.core.wmem_max = 8388608 net.ipv4.tcp_wmem = 4096 65535 8388608 net.ipv4.tcp_mem = 8388608 8388608 8388608 net.core.optmem_max = 40960
如果希望屏蔽别人 ping 你的主机,则加入以下代码:
# Disable ping requests
net.ipv4.icmp_echo_ignore_all = 1
编辑完成后,请执行以下命令使变动立即生效:
/sbin/sysctl -p
/sbin/sysctl -w net.ipv4.route.flush=1
###################
所有rfc相关的选项都是默认启用的,因此网上的那些还自己写rfc支持的都可以扔掉了:)
###############################
net.inet.ip.sourceroute=0
net.inet.ip.accept_sourceroute=0
#############################
通过源路由,攻击者可以尝试到达内部IP地址 --包括RFC1918中的地址,所以
不接受源路由信息包可以防止你的内部网络被探测。
#################################
net.inet.tcp.drop_synfin=1
###################################
安全参数,编译内核的时候加了options TCP_DROP_SYNFIN才可以用,可以阻止某些OS探测。
##################################
kern.maxvnodes=8446
#################http://www.bsdlover.cn#########
vnode 是对文件或目录的一种内部表达。 因此, 增加可以被操作系统利用的 vnode 数量将降低磁盘的 I/O。
一般而言, 这是由操作系统自行完成的,也不需要加以修改。但在某些时候磁盘 I/O 会成为瓶颈,
而系统的 vnode 不足, 则这一配置应被增加。此时需要考虑是非活跃和空闲内存的数量。
要查看当前在用的 vnode 数量:
# sysctl vfs.numvnodes
vfs.numvnodes: 91349
要查看最大可用的 vnode 数量:
# sysctl kern.maxvnodes
kern.maxvnodes: 100000
如果当前的 vnode 用量接近最大值,则将 kern.maxvnodes 值增大 1,000 可能是个好主意。
您应继续查看 vfs.numvnodes 的数值, 如果它再次攀升到接近最大值的程度,
仍需继续提高 kern.maxvnodes。 在 top(1) 中显示的内存用量应有显著变化,
更多内存会处于活跃 (active) 状态。
####################################
kern.maxproc: 964
#################http://www.bsdlover.cn#########
Maximum number of processes
####################################
kern.maxprocperuid: 867
#################http://www.bsdlover.cn#########
Maximum processes allowed per userid
####################################
因为我的maxusers设置的是256,20+16maxusers=4116。
maxprocperuid至少要比maxproc少1,因为init(8) 这个系统程序绝对要保持在运作状态。
我给它设置的2068。
kern.maxfiles: 1928
#################http://www.bsdlover.cn#########
系统中支持最多同时开启的文件数量,如果你在运行数据库或大的很吃描述符的进程,那么应该设置在20000以上,
比如kde这样的桌面环境,它同时要用的文件非常多。
一般推荐设置为32768或者65536。
####################################
kern.argmax: 262144
#################http://www.bsdlover.cn#########
maximum number of bytes (or characters) in an argument list.
命令行下最多支持的参数,比如你在用find命令来批量删除一些文件的时候
find . -name ".old" -delete,如果文件数超过了这个数字,那么会提示你数字太多的。
可以利用find . -name "*.old" -ok rm {} \;来删除。
默认的参数已经足够多了,因此不建议再做修改。
####################################
kern.securelevel: -1
#################http://www.bsdlover.cn#########
-1:这是系统默认级别,没有提供任何内核的保护错误;
0:基本上作用不多,当你的系统刚启动就是0级别的,当进入多用户模式的时候就自动变成1级了。
1:在这个级别上,有如下几个限制:
a. 不能通过kldload或者kldunload加载或者卸载可加载内核模块;
b. 应用程序不能通过/dev/mem或者/dev/kmem直接写内存;
c. 不能直接往已经装在(mounted)的磁盘写东西,也就是不能格式化磁盘,但是可以通过标准的内核接口执行写操作;
d. 不能启动X-windows,同时不能使用chflags来修改文件属性;
2:在 1 级别的基础上还不能写没装载的磁盘,而且不能在1秒之内制造多次警告,这个是防止DoS控制台的;
3:在 2 级别的级别上不允许修改IPFW防火墙的规则。
如果你已经装了防火墙,并且把规则设好了,不轻易改动,那么建议使用3级别,如果你没有装防火墙,而且还准备装防火墙的话,不建议使用。
我们这里推荐使用 2 级别,能够避免比较多对内核攻击。
####################################
kern.maxfilesperproc: 1735
#################http://www.bsdlover.cn#########
每个进程能够同时打开的最大文件数量,网上很多资料写的是32768
除非用异步I/O或大量线程,打开这么多的文件恐怕是不太正常的。
我个人建议不做修改,保留默认。
####################################
kern.ipc.maxsockbuf: 262144
#################http://www.bsdlover.cn#########
最大的套接字缓冲区,网上有建议设置为2097152(2M)、8388608(8M)的。
我个人倒是建议不做修改,保持默认的256K即可,缓冲区大了可能造成碎片、阻塞或者丢包。
####################################
kern.ipc.somaxconn: 128
#################http://www.bsdlover.cn#########
最大的等待连接完成的套接字队列大小,即并发连接数。
高负载服务器和受到Dos攻击的系统也许会因为这个队列被塞满而不能提供正常服务。
默认为128,推荐在1024-4096之间,根据机器和实际情况需要改动,数字越大占用内存也越大。
####################################
kern.ipc.nmbclusters: 4800
#################http://www.bsdlover.cn#########
这个值用来调整系统在开机后所要分配给网络 mbufs 的 cluster 数量,
由于每个 cluster 大小为 2K,所以当这个值为 1024 时,也是会用到 2MB 的核心内存空间。
假设我们的网页同时约有 1000 个联机,而 TCP 传送及接收的暂存区大小都是 16K,
则最糟的情况下,我们会需要 (16K+16K) * 1024,也就是 32MB 的空间,
然而所需的 mbufs 大概是这个空间的二倍,也就是 64MB,所以所需的 cluster 数量为 64MB/2K,也就是 32768。
对于内存有限的机器,建议值是 1024 到 4096 之间,而当拥有海量存储器空间时,我们可以将它设定为 4096 到 32768 之间。
我们可以使用 netstat 这个指令并加上参数 -m 来查看目前所使用的 mbufs 数量。
要修改这个值必须在一开机就修改,所以只能在 /boot/loader.conf 中加入修改的设定
kern.ipc.nmbclusters=32768
####################################
kern.ipc.shmmax: 33554432
#################http://www.bsdlover.cn#########
共享内存和信号灯("System VIPC")如果这些过小的话,有些大型的软件将无法启动
安装xine和mplayer提示的设置为67108864,即64M,
如果内存多的话,可以设置为134217728,即128M
####################################
kern.ipc.shmall: 8192
#################http://www.bsdlover.cn#########
共享内存和信号灯("System VIPC")如果这些过小的话,有些大型的软件将无法启动
安装xine和mplayer提示的设置为32768
####################################
kern.ipc.shm_use_phys: 0
#################http://www.bsdlover.cn#########
如果我们将它设成 1,则所有 System V 共享内存 (share memory,一种程序间沟通的方式)部份都会被留在实体的内存 (physical memory) 中,
而不会被放到硬盘上的 swap 空间。我们知道物理内存的存取速度比硬盘快许多,而当物理内存空间不足时,
部份数据会被放到虚拟的内存上,从物理内存和虚拟内存之间移转的动作就叫作 swap。如果时常做 swap 的动作,
则需要一直对硬盘作 I/O,速度会很慢。因此,如果我们有大量的程序 (数百个) 需要共同分享一个小的共享内存空间,
或者是共享内存空间很大时,我们可以将这个值打开。
这一项,我个人建议不做修改,除非你的内存非常大。
####################################
kern.ipc.shm_allow_removed: 0
#################http://www.bsdlover.cn#########
共享内存是否允许移除?这项似乎是在fb下装vmware需要设置为1的,否则会有加载SVGA出错的提示
作为服务器,这项不动也罢。
####################################
kern.ipc.numopensockets: 12
#################http://www.bsdlover.cn#########
已经开启的socket数目,可以在最繁忙的时候看看它是多少,然后就可以知道maxsockets应该设置成多少了。
####################################
kern.ipc.maxsockets: 1928
#################http://www.bsdlover.cn#########
这是用来设定系统最大可以开启的 socket 数目。如果您的服务器会提供大量的 FTP 服务,
而且常快速的传输一些小档案,您也许会发现常传输到一半就中断。因为 FTP 在传输档案时,
每一个档案都必须开启一个 socket 来传输,但关闭 socket 需要一段时间,如果传输速度很快,
而档案又多,则同一时间所开启的 socket 会超过原本系统所许可的值,这时我们就必须把这个值调大一点。
除了 FTP 外,也许有其它网络程序也会有这种问题。
然而,这个值必须在系统一开机就设定好,所以如果要修改这项设定,我们必须修改 /boot/loader.conf 才行
kern.ipc.maxsockets="16424"
####################################
kern.ipc.nsfbufs: 1456
#################http://www.bsdlover.cn#########
经常使用 sendfile(2) 系统调用的繁忙的服务器,
有必要通过 NSFBUFS 内核选项或者在 /boot/loader.conf (查看 loader(8) 以获得更多细节) 中设置它的值来调节 sendfile(2) 缓存数量。
这个参数需要调节的普通原因是在进程中看到 sfbufa 状态。sysctl kern.ipc.nsfbufs 变量在内核配置变量中是只读的。
这个参数是由 kern.maxusers 决定的,然而它可能有必要因此而调整。
在/boot/loader.conf里加入
kern.ipc.nsfbufs="2496"
####################################
kern.maxusers: 59
#################http://www.bsdlover.cn#########
maxusers 的值决定了处理程序所容许的最大值,20+16*maxusers 就是你将得到的所容许处理程序。
系统一开机就必须要有 18 个处理程序 (process),即便是简单的执行指令 man 又会产生 9 个 process,
所以将这个值设为 64 应该是一个合理的数目。
如果你的系统会出现 proc table full 的讯息的话,可以就把它设大一点,例如 128。
除非您的系统会需要同时开启很多档案,否则请不要设定超过 256。
可以在 /boot/loader.conf 中加入该选项的设定,
kern.maxusers=256
####################################
kern.coredump: 1
#################http://www.bsdlover.cn#########
如果设置为0,则程序异常退出时不会生成core文件,作为服务器,不建议这样。
####################################
kern.corefile: %N.core
#################http://www.bsdlover.cn#########
可设置为kern.corefile="/data/coredump/%U-%P-%N.core"
其中 %U是UID,%P是进程ID,%N是进程名,当然/data/coredump必须是一个实际存在的目录
####################################
vm.swap_idle_enabled: 0
vm.swap_idle_threshold1: 2
vm.swap_idle_threshold2: 10
#########################
在有很多用户进入、离开系统和有很多空闲进程的大的多用户系统中很有用。
可以让进程更快地进入内存,但它会吃掉更多的交换和磁盘带宽。
系统默认的页面调度算法已经很好了,最好不要更改。
########################
vfs.ufs.dirhash_maxmem: 2097152
#########################
默认的dirhash最大内存,默认2M
增加它有助于改善单目录超过100K个文件时的反复读目录时的性能
建议修改为33554432(32M)
#############################
vfs.vmiodirenable: 1
#################
这个变量控制目录是否被系统缓存。大多数目录是小的,在系统中只使用单个片断(典型的是1K)并且在缓存中使用的更小 (典型的是512字节)。
当这个变量设置为关闭 (0) 时,缓存器仅仅缓存固定数量的目录,即使您有很大的内存。
而将其开启 (设置为1) 时,则允许缓存器用 VM 页面缓存来缓存这些目录,让所有可用内存来缓存目录。
不利的是最小的用来缓存目录的核心内存是大于 512 字节的物理页面大小(通常是 4k)。
我们建议如果您在运行任何操作大量文件的程序时保持这个选项打开的默认值。
这些服务包括 web 缓存,大容量邮件系统和新闻系统。
尽管可能会浪费一些内存,但打开这个选项通常不会降低性能。但还是应该检验一下。
####################
vfs.hirunningspace: 1048576
############################
这个值决定了系统可以将多少数据放在写入储存设备的等候区。通常使用默认值即可,
但当我们有多颗硬盘时,我们可以将它调大为 4MB 或 5MB。
注意这个设置成很高的值(超过缓存器的写极限)会导致坏的性能。
不要盲目的把它设置太高!高的数值会导致同时发生的读操作的迟延。
#############################
vfs.write_behind: 1
#########################
这个选项预设为 1,也就是打开的状态。在打开时,在系统需要写入数据在硬盘或其它储存设备上时,
它会等到收集了一个 cluster 单位的数据后再一次写入,否则会在一个暂存区空间有写入需求时就立即写到硬盘上。
这个选项打开时,对于一个大的连续的文件写入速度非常有帮助。但如果您遇到有很多行程延滞在等待写入动作时,您可能必须关闭这个功能。
############################
net.local.stream.sendspace: 8192
##################################
本地套接字连接的数据发送空间
建议设置为65536
###################################
net.local.stream.recvspace: 8192
##################################
本地套接字连接的数据接收空间
建议设置为65536
###################################
net.inet.ip.portrange.lowfirst: 1023
net.inet.ip.portrange.lowlast: 600
net.inet.ip.portrange.first: 49152
net.inet.ip.portrange.last: 65535
net.inet.ip.portrange.hifirst: 49152
net.inet.ip.portrange.hilast: 65535
###################
以上六项是用来控制TCP及UDP所使用的port范围,这个范围被分成三个部份,低范围、预设范围、及高范围。
这些是你的服务器主动发起连接时的临时端口的范围,预设的已经1万多了,一般的应用就足够了。
如果是比较忙碌的FTP server,一般也不会同时提供给1万多人访问的,
当然如果很不幸,你的服务器就要提供很多,那么可以修改first的值,比如直接用1024开始
#########################
net.inet.ip.redirect: 1
#########################
设置为0,屏蔽ip重定向功能
###########################
net.inet.ip.rtexpire: 3600
net.inet.ip.rtminexpire: 10
########################
很多apache产生的CLOSE_WAIT状态,这种状态是等待客户端关闭,但是客户端那边并没有正常的关闭,于是留下很多这样的东东。
建议都修改为2
#########################
net.inet.ip.intr_queue_maxlen: 50
########################
Maximum size of the IP input queue,如果下面的net.inet.ip.intr_queue_drops一直在增加,
那就说明你的队列空间不足了,那么可以考虑增加该值。
##########################
net.inet.ip.intr_queue_drops: 0
####################
Number of packets dropped from the IP input queue,如果你sysctl它一直在增加,
那么增加net.inet.ip.intr_queue_maxlen的值。
#######################
net.inet.ip.fastforwarding: 0
#############################
如果打开的话每个目标地址一次转发成功以后它的数据都将被记录进路由表和arp数据表,节约路由的计算时间
但会需要大量的内核内存空间来保存路由表。
如果内存够大,打开吧,呵呵
#############################
net.inet.ip.random_id: 0
#####################
默认情况下,ip包的id号是连续的,而这些可能会被攻击者利用,比如可以知道你nat后面带了多少主机。
如果设置成1,则这个id号是随机的,嘿嘿。
#####################
net.inet.icmp.maskrepl: 0
############################
防止广播风暴,关闭其他广播探测的响应。默认即是,无须修改。
###############################
net.inet.icmp.icmplim: 200
##############################
限制系统发送ICMP速率,改为100吧,或者保留也可,并不会给系统带来太大的压力。
###########################
net.inet.icmp.icmplim_output: 1
###################################
如果设置成0,就不会看到提示说Limiting icmp unreach response from 214 to 200 packets per second 等等了
不过禁止输出容易让我们忽视攻击的存在。这个自己看着办吧。
######################################
net.inet.icmp.drop_redirect: 0
net.inet.icmp.log_redirect: 0
###################################
设置为1,屏蔽ICMP重定向功能
###################################
net.inet.icmp.bmcastecho: 0
############################
防止广播风暴,关闭广播ECHO响应,默认即是,无须修改。
###############################
net.inet.tcp.mssdflt: 512
net.inet.tcp.minmss: 216
###############################
数据包数据段最小值,以上两个选项最好不动!或者只修改mssdflt为1460,minmss不动。
原因详见http://www.bsdlover.cn/security/2007/1211/article_4.html
#############################
net.inet.tcp.keepidle: 7200000
######################
TCP的套接字的空闲时间,默认时间太长,可以改为600000(10分钟)。
##########################
net.inet.tcp.sendspace: 32768
#################http://www.bsdlover.cn#########
最大的待发送TCP数据缓冲区空间,应用程序将数据放到这里就认为发送成功了,系统TCP堆栈保证数据的正常发送。
####################################
net.inet.tcp.recvspace: 65536
###################################
最大的接受TCP缓冲区空间,系统从这里将数据分发给不同的套接字,增大该空间可提高系统瞬间接受数据的能力以提高性能。
###################################
这二个选项分别控制了网络 TCP 联机所使用的传送及接收暂存区的大小。预设的传送暂存区为 32K,而接收暂存区为 64K。
如果需要加速 TCP 的传输,可以将这二个值调大一点,但缺点是太大的值会造成系统核心占用太多的内存。
如果我们的机器会同时服务数百或数千个网络联机,那么这二个选项最好维持默认值,否则会造成系统核心内存不足。
但如果我们使用的是 gigabite 的网络,将这二个值调大会有明显效能的提升。
传送及接收的暂存区大小可以分开调整,
例如,假设我们的系统主要做为网页服务器,我们可以将接收的暂存区调小一点,并将传送的暂存区调大,如此一来,我们就可以避免占去太多的核心内存空间。
net.inet.udp.maxdgram: 9216
#########################
最大的发送UDP数据缓冲区大小,网上的资料大多都是65536,我个人认为没多大必要,
如果要调整,可以试试24576。
##############################
net.inet.udp.recvspace: 42080
##################
最大的接受UDP缓冲区大小,网上的资料大多都是65536,我个人认为没多大必要,
如果要调整,可以试试49152。
#######################
以上四项配置通常不会导致问题,一般说来网络流量是不对称的,因此应该根据实际情况调整,并观察其效果。
如果我们将传送或接收的暂存区设为大于 65535,除非服务器本身及客户端所使用的操作系统都支持 TCP 协议的 windows scaling extension (请参考 RFC 1323 文件)。
FreeBSD默认已支持 rfs1323 (即 sysctl 的 net.inet.tcp.rfc1323 选项)。
###################################################
net.inet.tcp.log_in_vain: 0
##################
记录下任何TCP连接,这个一般情况下不应该更改。
####################
net.inet.tcp.blackhole: 0
##################################
建议设置为2,接收到一个已经关闭的端口发来的所有包,直接drop,如果设置为1则是只针对TCP包
#####################################
net.inet.tcp.delayed_ack: 1
###########################
当一台计算机发起TCP连接请求时,系统会回应ACK应答数据包。
该选项设置是否延迟ACK应答数据包,把它和包含数据的数据包一起发送。
在高速网络和低负载的情况下会略微提高性能,但在网络连接较差的时候,
对方计算机得不到应答会持续发起连接请求,反而会让网络更加拥堵,降低性能。
因此这个值我建议您看情况而定,如果您的网速不是问题,可以将封包数量减少一半
如果网络不是特别好,那么就设置为0,有请求就先回应,这样其实浪费的网通、电信的带宽速率而不是你的处理时间:)
############################
net.inet.tcp.inflight.enable: 1
net.inet.tcp.inflight.debug: 0
net.inet.tcp.inflight.rttthresh: 10
net.inet.tcp.inflight.min: 6144
net.inet.tcp.inflight.max: 1073725440
net.inet.tcp.inflight.stab: 20
###########################
限制 TCP 带宽延迟积和 NetBSD 的 TCP/Vegas 类似。
它可以通过将 sysctl 变量 net.inet.tcp.inflight.enable 设置成 1 来启用。
系统将尝试计算每一个连接的带宽延迟积,并将排队的数据量限制在恰好能保持最优吞吐量的水平上。
这一特性在您的服务器同时向使用普通调制解调器,千兆以太网,乃至更高速度的光与网络连接 (或其他带宽延迟积很大的连接) 的时候尤为重要,
特别是当您同时使用滑动窗缩放,或使用了大的发送窗口的时候。
如果启用了这个选项,您还应该把 net.inet.tcp.inflight.debug 设置为 0 (禁用调试),
对于生产环境而言, 将 net.inet.tcp.inflight.min 设置成至少 6144 会很有好处。
然而, 需要注意的是,这个值设置过大事实上相当于禁用了连接带宽延迟积限制功能。
这个限制特性减少了在路由和交换包队列的堵塞数据数量,也减少了在本地主机接口队列阻塞的数据的数量。
在少数的等候队列中、交互式连接,尤其是通过慢速的调制解调器,也能用低的 往返时间操作。
但是,注意这只影响到数据发送 (上载/服务端)。对数据接收(下载)没有效果。
调整 net.inet.tcp.inflight.stab 是 不 推荐的。
这个参数的默认值是 20,表示把 2 个最大包加入到带宽延迟积窗口的计算中。
额外的窗口似的算法更为稳定,并改善对于多变网络环境的相应能力,
但也会导致慢速连接下的 ping 时间增长 (尽管还是会比没有使用 inflight 算法低许多)。
对于这些情形, 您可能会希望把这个参数减少到 15, 10, 或 5;
并可能因此而不得不减少 net.inet.tcp.inflight.min (比如说, 3500) 来得到希望的效果。
减少这些参数的值, 只应作为最后不得已时的手段来使用。
############################
net.inet.tcp.syncookies: 1
#########################
SYN cookies是一种用于通过选择加密的初始化TCP序列号,可以对回应的包做验证来降低SYN'洪水'攻击的影响的技术。
默认即是,不需修改
########################
net.inet.tcp.msl: 30000
#######################
这个值网上很多文章都推荐的7500,
还可以改的更小一些(如2000或2500),这样可以加快不正常连接的释放过程(三次握手2秒、FIN_WAIT4秒)。
#########################
net.inet.tcp.always_keepalive: 1
###########################
帮助系统清除没有正常断开的TCP连接,这增加了一些网络带宽的使用,但是一些死掉的连接最终能被识别并清除。
死的TCP连接是被拨号用户存取的系统的一个特别的问题,因为用户经常断开modem而不正确的关闭活动的连接。
#############################
net.inet.udp.checksum: 1
#########################
防止不正确的udp包的攻击,默认即是,不需修改
##############################
net.inet.udp.log_in_vain: 0
#######################
记录下任何UDP连接,这个一般情况下不应该修改。
#######################
net.inet.udp.blackhole: 0
####################
建议设置为1,接收到一个已经关闭的端口发来的所有UDP包直接drop
#######################
net.inet.raw.maxdgram: 8192
#########################
Maximum outgoing raw IP datagram size
很多文章建议设置为65536,好像没多大必要。
######################################
net.inet.raw.recvspace: 8192
######################
Maximum incoming raw IP datagram size
很多文章建议设置为65536,好像没多大必要。
#######################
net.link.ether.inet.max_age: 1200
####################
调整ARP清理的时间,通过向IP路由缓冲填充伪造的ARP条目可以让恶意用户产生资源耗竭和性能减低攻击。
这项似乎大家都未做改动,我建议不动或者稍微减少,比如300(HP-UX默认的5分钟)
#######################
net.inet6.ip6.redirect: 1
###############################
设置为0,屏蔽ipv6重定向功能
###########################
net.isr.direct: 0
#################http://www.bsdlover.cn#########
所有MPSAFE的网络ISR对包做立即响应,提高网卡性能,设置为1。
####################################
hw.ata.wc: 1
#####################
这个选项用来打开 IDE 硬盘快取。当打开时,如果有数据要写入硬盘时,硬盘会假装已完成写入,并将数据快取起来。
这种作法会加速硬盘的存取速度,但当系统异常关机时,比较容易造成数据遗失。
不过由于关闭这个功能所带来的速度差异实在太大,建议还是保留原本打开的状态吧,不做修改。
###################
security.bsd.see_other_uids: 1
security.bsd.see_other_gids: 1
#####################
不允许用户看到其他用户的进程,因此应该改成0,
#######################
写得很好,自己亲自实践了,效果不错,感谢作者!原文地址:http://blog.csdn.net/21aspnet/article/details/6584792
X浏览器1.4.4 build 40(安卓版)-884Kb,轻巧,强大,支持自动代理模式(翻墙模式) 翻墙工具
好久没更新了,今天送给大家一个浏览器玩玩,安卓,苹果,Mac,Windows 三平台支持的,免费加速器下载 2020最新可用 下载链接:点击下载
很好玩的浏览器仅有884Kb,轻巧,强大,支持自动代理模式(查资料模式)。
X浏览器apk是你手机上的一款帮你省电省内存的手机急速浏览器,它没有任何的插件,没有后台进程,让你轻松浏览,是你手机看电影,看小说的神器。


X浏览器安卓版功能特色:
1、急速浏览,一键开启关闭,绝不残留。
2、智能网址搜索。
3、全屏阅读,一秒变阅读器。
4、支持自动代理浏览(查资料)。
5、支持设置UA(默认,iPhone,iPad,桌面)。
6、支持沉浸模式(阅读小说全屏爽歪歪)。
更多功能等你发现。。。


开启自动代理模式(查资料模式):
打开设置,然后在顶部的地址栏里面将:x:setting 修改成 x:info 即可设置自动代理,广告过滤等等。
我试了开启广告过滤和自动代理模式后,访问速度和效果都很好,推荐大家下载使用。轻巧,强大!
最近比较忙,更新会比较慢,感谢大家的支持。
下载地址:http://pan.baidu.com/s/1qWoV572
或者是附件下载:
emlog静态化插件有可能出现的几个问题/bug及解决方法 emlog
今天旧城博客来说加友链,我添加了之后发现,根本没有显示,ctrl+F5刷新,清空浏览器cookies,换浏览器,都试过了,还是没有显示,这是我又想是不是因为CDN的原因,于是关掉CDN,发现问题依旧存在;但是由于当时有事情没时间解决,就放了一下,就在刚刚,朋友们的评论信息也不能及时显示了,同时还测试了一下更换模板,发现居后台换了模板之后,去首页刷新还是原来的模板,这可把我吓一跳,还以为是服务器出问题了,于是登陆服务器,都检查了一遍,发现没有什么事儿。。。我就纳闷了。。。试了一下后台数据的更新缓存,一样没有效果。
就在准备找人询问原因的时候,突然灵光一闪!嘿嘿,插件!嗯,我试着把emlog静态化插件禁止了,更新缓存,首页已刷新,OK,各项恢复正常。。。其实之前也遇到过因为这个emlog静态化插件和CSRF保护脚本插件有冲突,开启CSRF保护脚本插件的时候使用emlog静态化插件就会出现权限问题403 forbidden这类的问题。之前还遇到过类似的插件冲突问题,插件打开顺序不同,结果显示的界面就会不同,或者是功能就会不同程度的变化。。。
总结一下:emlog程序很简洁,通过插件可以是程序变得功能多且强大,但是就会导致程序变慢,各种JS冲突,权限分配、判断等等一系列问题,所以当你的emlog遇到了一些小问题问题(显示,排版等)的时候,可以尝试先把所有的插件禁止了,如果你的插件比较多,可以选择上传官方的emlog工具箱插件,可以一键禁止所有已开启的插件,当然你在排除问题之前可以先备份一下相关数据,到时候找到了问题直接恢复数据,再去禁用相关插件就可以了,这样省时省力。最后呢,希望新版本的emlog6正式版发布的时候可以解决这些问题,同时呢,也希望各位emlog的开发者能够注意,考虑这些问题,在制作插件的时候多考虑一下插件的兼容性。以上内容只是我的个人见解,希望没有给各位看官带来不快,如有,对不起,请 Ctrl+W 关闭当前页。
自动压缩、加密 CSS/JavaScript 优化网站性能 PHP
关于压缩
压缩 CSS 的方法, 无外乎缩写代码和清除多余字符来实现, 平时只要养成使用缩写的技巧就可以明显减少最终代码的整体大小. 在此我就不做过多的描述, 后文也会有简单的压缩代码.
相比于前者, JavaScript 的压缩方式就比较丰富工具也很多, 常用的有: Packer/YUI-compressor/Dojo Compressor 等, 本人比较喜欢用 Packer 来压缩, 压缩比例可以达到 50% 上下.
我不知道读者是如何对 CSS/JavaScript 进行处理的, 但在此之前我都是线下压缩然后在上传, 但还是有些麻烦且不便于管理. 于是最近正好找到一个 Packer 的后端类, 在不改动原 CSS/JavaScript 的前提下实时压缩文件并输出, 可以更好的解决我目前的困扰.
实现过程
首先在下载:packer.php-1.1.zip 并解压 class.JavaScriptPacker.php 到你的当前主题目录, 然后在相同位置创建compress.php 文件, 内容如下:
<?php
'javascript', 'css' => 'css');
if (file_exists($path)) { // 判断文件存在的情况下在执行压缩工作
Header('Content-Type: text/' . $head[$info] . '; charset=utf-8'); // 必需定义相应的文件头
$script = file_get_contents($path); //读取文件
if ($info != 'css') { // 判断不同的文件类型做处理
require 'class.JavaScriptPacker.php'; // 引用 Packer 类
$packer = new JavaScriptPacker($script, 'Normal', true, false); // 设置压缩参数
$packed = $packer->pack(); // 压缩并写入变量
} else { // 处理 CSS 文件
$packer = preg_replace("!/\*[^*]*\*+([^/][^*]*\*+)*/!", "", $script); // 清除多余注释
$packed = str_replace(array("\r\n", "\r", "\n", "\t", " ", " ", " "), null, $packer); // 清除多余换行、空格、缩进符
}
echo $packed; // 输出所压缩的内容
}
;?>
然后在相同的位置创建一个 .htaccess 文件, 内容如下:
RewriteEngine On
RewriteRule (.*.(js|css))$ /compress.php?name=$1
后记
该方法在自己的vps+Apache 环境下通过, 直接访问相应文件的绝对路径就会自动压缩并输出, 但是如果你的主机不支持 Rewrite 功能的话, 可以跳过创建 .htaccess 然后通过 http://youdomain.com/content/templates/主题目录/compress.php?name=文件名称.css/js 来调用文件.
-
admin 约 20 小时前
@東咩:无
-
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
哥,还能再分享不 百度账号:東咩
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。
-
admin 2024-03-28 22:38
@人大代表:卧槽 别搞我...
-
24年的新闻,你22年爆出来了。厉害了,大哥。

