分享24个超赞的CSS+html5代码片段 PHP
分享24个超赞的CSS+html5代码片段,如果你做模板用上其中一些CSS片段,我保证你的模板会美上很多的!
CodePen是一个网站前端设计开发平台,是一个针对网站前端代码设计的开发工具,提供多种效果的网站前端代码设计工具和丰富的案例特效代码。用户可以在各种现成的demo基础上Fork后开发自己的前端设计,也可以把你的Demo设计分享给其他人。
都是一些前端的设计,有些特效非常漂亮炫酷,有些是自适应的扁平化布局设计,有些是纯CSS实现的图标,有些令人惊艳的切换旋转效果。你可以自己去慢慢发现这些Demo的美妙之处。
Pure CSS3 MacBook Air with Thunderbird Display and Keyboard

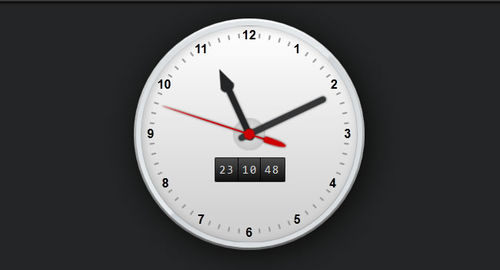
CSS3 Working Clock
这是个CSS3实现的时钟效果,使用的是CSS3动画特效,没有任何图片和JS.
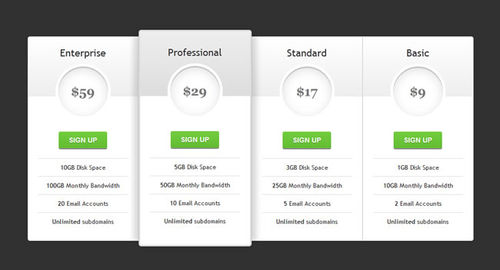
CSS3 Pricing Table
CSS Loader
Demo
Twitter Button Concept
CSS3 Loading Animation
Pure CSS3 Vertical Menu with Hover Effect
CSS3 Stamp effect using radial gradients
I Love Blur
Social Navigation
Login
Calendar
Social Footer
Parallax Landscape
CSS3 Thermometer
CSS-Only Responsive Layout with Smooth Transitions
Flat CSS3 Weather Widget
Flat Responsive Sliding Boxes
Tiny CSS3 Round Breadcrumb
CSS3 Hover Effect using :after Psuedo Element
Flat UI Elements
CSS Flat Button Shapes
Email UI
Flat Icons CSS














总结一下EMLOG获取固定数量的网站标签几种方法 PHP
标签功能是WEB发展的产物,EMLOG当然也具备文章添加标签的功能。而且在EMLOG的侧边栏组件中,用户也可以手动增加该模块。
不过,有一个小小的问题是,侧边栏组件中的标签默认是显示网站所有标签的,如果你的标签过多,势必会影响到网站的美观度。我的博客就是这样,标签太多了,模板默认是全部显示的,严重影响美观!所以Mrxn就网上搜索和自己实践,修改,验证,总结出在emlog中如何来获取固定数量的网站标签.
No.1
<?php
// 获取EMLOG固定数量网站标签
// Mrxn's Blog 收集整理发布 mrxn.net
function getTags($num){
global $CACHE;
$tag_cache = $CACHE->readCache('tags');
foreach($tag_cache as $key => $value):
if($key < $num):
?>
<span><a href="<?php echo Url::tag($value['tagurl']); ?>" title="<?php echo $value['usenum']; ?> 篇文章">
<?php echo $value['tagname']; ?></a></span>
<?php
endif;
endforeach;
}
?>
如上代码既实现了获取EMLOG网站固定数量标签的功能呢,参数$num即为用户设置的标签个数。使用方法是先将该段代码写在模板文件module.php当中,然后再模板前台文件中写入一行调用该函数的代码即可,如下:
<?php
//把这一段代码写到模板文件中即可实现调用10个网站标签
getTags(10);
?>
另外,如果希望调用的标签随机显示,则需要使用shuffle()函数进行一次顺序的打乱。函数代码如下,相对于之前来说仅仅只添加了一行代码:
<?php
// 获取EMLOG固定数量网站标签(随机排序)
// Mrxn's Blog 收集整理发布 mrxn.net
function getTags($num){
global $CACHE;
$tag_cache = $CACHE->readCache('tags');
shuffle($tag_cache); //添加这行代码实现标签随机排序
foreach($tag_cache as $key => $value):
if($key < $num):
?>
<span><a href="<?php echo Url::tag($value['tagurl']); ?>" title="<?php echo $value['usenum']; ?> 篇文章">
<?php echo $value['tagname']; ?></a></span>
<?php
endif;
endforeach;
}
?>
No.2
注:这个需要改动内核文件,请emer注意,新手慎用.Mrxn问题提示:使用之前做好备份!
emlog使用缓存的方法,事先将全部标签存放在\content\cache\tags缓存文件中,读取的时候使用模板中的$tag_cache = $CACHE->readCache('newtags')读取。
1.找到\include\lib\cache.php并打开
2.找到private function mc_tags()函数
你会发现他的sql语句是将你设置的所有标签全部查询出来,如果你的标签设置很多时候,打开一次就查询一次,显然不好。所以为将他改为每次随机查询30个标签出来,让他放到缓存文件中。
3.将$query = $this->db->query("SELECT gid FROM " . DB_PREFIX . "tag");改为$query = $this->db->query("SELECT gid FROM " . DB_PREFIX . "tag ORDER BY RAND() LIMIT 30");
4.将$query = $this->db->query("SELECT tagname,gid FROM " . DB_PREFIX . "tag");改为$query = $this->db->query("SELECT tagname,gid FROM " . DB_PREFIX . "tag ORDER BY RAND() LIMIT 30");
这样每次显示出来的标签都是随机抽出来的30个,当然这个数字你可以自己改,你想显示多少就改成多少,而且你可以通过更改查询条件来指定你要显示的标签,比如你如果想显示的30个标签不是随机的,而是你最新的30个,只需要将后面查询条件改为:
DESC LIMIT 0,30这样就行了。
No.3可以调整标签字体的大小,颜色
//widget:标签
function widget_tag($title){
global $CACHE;
$tag_cache = $CACHE->readCache('tags');?>
<li>
<h3><span><?php echo $title; ?></span></h3>
<ul id="blogtags">
<?php
foreach($tag_cache as $value):
$minFontSize=12; //最小字体大小,可根据需要自行更改
$maxFontSize=20; //最大字体大小,可根据需要自行更改
$style='font-size:'.($minFontSize+lcg_value()*(abs($maxFontSize-$minFontSize))).'px;color:#'.dechex(rand(0,255)).dechex(rand(0,196)).dechex(rand(0,255));
$text=" <a href='".Url::tag($value['tagurl'])."' title='".$value['usenum']."篇日志'><span style='".$style."'>".$value['tagname']."</span></a>";
echo $text;
endforeach;
?>
</ul>
</li>
<?php }?>
让emlog侧边栏显示彩色标签,随机显示标签,数量多少有你控制 PHP
让emlog侧边栏显示彩色标签,随机显示标签,数量多少有你控制,本教程由 Mrxn 倾情发布,
嘿嘿,废话不多说,下面进入正题:
0X1:
打开模板的module.php,找到:widget:标签 字样,然后在
$tag_cache = $CACHE->readCache('tags');
下面添加如下两行代码:
$tag_cache = array_slice($tag_cache,0,42); //设置标签显示数量(0,num) shuffle($tag_cache);?> <!--将数组打乱,即让它随机显示 <-->
0X2 继续往下找到如下代码:
<?php foreach($tag_cache as $value):?>
将其修改成如下代码:
<?php foreach($tag_cache as $value): $color = dechex(rand(0,16777215));?> //设置颜色值范围,温馨提示:标签多颜色值范围大点好,反之,亦然
0X3: 最后一步,颜色效果引用:
<a href="<?php echo Url::tag($value['tagurl']); ?>" style="color:#<?php echo $color;//在标签链接href里面应用颜色样式 ;?>;"><?php echo $value['tagname']; ?>(<?php echo$value['usenum'];?>)</a>
最终效果就如我博客右侧的标签效果一样,刷新一次标签顺序变换一次,颜色也变换一次:

如有不懂得,欢迎留言交流,这是我的代码:
curl命令使用详解 代码人生
因为要用百度的sitemap所以得自己写个sitemap,百度说:
将xml数据写入一个本地文件,比如thread.xml,然后调用curl命令:
使用php、python、java等可以参照这个过程推送结构化数据。
于是就开始去各种搜索,并且找到了,自己也正在写百度的sitemap...... 用度娘的收录好,利于SEO......
可以看作命令行浏览器
1、开启gzip请求
curl -I http://www.sina.com.cn/ -H
Accept-Encoding:gzip,defalte
2、监控网页的响应时间
curl -o /dev/null -s -w "time_connect:
%{time_connect}\ntime_starttransfer:
%{time_starttransfer}\ntime_total: %{time_total}\n"
"http://www.kklinux.com"
3. 监控站点可用性
curl -o /dev/null -s -w %{http_code}
"http://www.kklinux.com"
4、以http1.0协议请求(默认为http1.1)
curl -0 ..............
$ curl
linuxidc.com">http://www.linuxidc.com
2)保存网页
$ curl http://www.linuxidc.com > page.html $ curl
-o page.html http://www.linuxidc.com
3)使用的proxy服务器及其端口:-x
$ curl -x 123.45.67.89:1080 -o page.html
http://www.linuxidc.com
4)使用cookie来记录session信息
$ curl -x 123.45.67.89:1080 -o page.html -D cookie0001.txt
http://www.linuxidc.com
option: -D
是把http的response里面的cookie信息存到一个特别的文件中去,这样,当页面被存到page.html的同时,cookie信息也被存到了cookie0001.txt里面了
使用option来把上次的cookie信息追加到http
request里面去:-b
$ curl -x 123.45.67.89:1080 -o page1.html -D cookie0002.txt -b
cookie0001.txt http://www.linuxidc.com
6)浏览器信息~~~~
随意指定自己这次访问所宣称的自己的浏览器信息: -A
curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x
123.45.67.89:1080 -o page.html -D cookie0001.txt
http://www.yahoo.com
这样,服务器端接到访问的要求,会认为你是一个运行在Windows
2000上的IE6.0,嘿嘿嘿,其实也许你用的是苹果机呢!
而"Mozilla/4.73 [en] (X11; U; Linux 2.2; 15
i686"则可以告诉对方你是一台PC上跑着的Linux,用的是Netscape
4.73,呵呵呵
7)
另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的referer地址就是第一次访问成功后的页面地
址。这样,服务器端只要发现对下载页面某次访问的referer地址不
是首页的地址,就可以断定那是个盗连了~~~~~
讨厌讨厌~~~我就是要盗连~~~~~!!
幸好curl给我们提供了设定referer的option: -e
curl -A "Mozilla/4.0
(compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e
"mail.yahoo.com" -o page.html -D cookie0001.txt
http://www.yahoo.com
这样,就可以骗对方的服务器,你是从mail.yahoo.com点击某个链接过来的了,呵呵呵
8)curl
下载文件
刚才讲过了,下载页面到一个文件里,可以使用 -o ,下载文件也是一样。
比如, curl -o 1.jpg
http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这里教大家一个新的option:
-O
大写的O,这么用: curl -O
http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这样,就可以按照服务器上的文件名,自动存在本地了!
再来一个更好用的。
如果screen1.JPG以外还有screen2.JPG、screen3.JPG、....、screen10.JPG需要下载,难不成还要让我们写一个script来完成这些操作?
不干!
在curl里面,这么写就可以了:
curl -O
http://cgi2.tky.3web.ne.jp/~zzh/screen[1-10].JPG
呵呵呵,厉害吧?!~~~
9)
再来,我们继续讲解下载!
curl -O
http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
这样产生的下载,就是
~zzh/001.JPG
~zzh/002.JPG
...
~zzh/201.JPG
~nick/001.JPG
~nick/002.JPG
...
~nick/201.JPG
够方便的了吧?哈哈哈
咦?高兴得太早了。
由于zzh/nick下的文件名都是001,002...,201,下载下来的文件重名,后面的把前面的文件都给覆盖掉了~~~
没关系,我们还有更狠的!
curl -o #2_#1.jpg
http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
--这是.....自定义文件名的下载?
--对头,呵呵!
#1是变量,指的是{zzh,nick}这部分,第一次取值zzh,第二次取值nick
#2代表的变量,则是第二段可变部分---[001-201],取值从001逐一加到201
这样,自定义出来下载下来的文件名,就变成了这样:
原来: ~zzh/001.JPG
---> 下载后: 001-zzh.JPG
原来: ~nick/001.JPG
---> 下载后:
001-nick.JPG
这样一来,就不怕文件重名啦,呵呵
9)
继续讲下载
我们平时在windows平台上,flashget这样的工具可以帮我们分块并行下载,还可以断线续传。
curl在这些方面也不输给谁,嘿嘿
比如我们下载screen1.JPG中,突然掉线了,我们就可以这样开始续传
curl -c -O
http://cgi2.tky.3wb.ne.jp/~zzh/screen1.JPG
当然,你不要拿个flashget下载了一半的文件来糊弄我~~~~别的下载软件的半截文件可不一定能用哦~~~
分块下载,我们使用这个option就可以了: -r
举例说明
比如我们有一个http://cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
要下载(赵老师的电话朗诵 :D )
我们就可以用这样的命令:
curl -r 0-10240 -o
"zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
&\
curl -r 10241-20480
-o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
&\
curl -r 20481-40960
-o "zhao.part1" http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
&\
curl -r 40961- -o
"zhao.part1"
http:/cgi2.tky.3web.ne.jp/~zzh/zhao1.mp3
这样就可以分块下载啦。
不过你需要自己把这些破碎的文件合并起来
如果你用UNIX或苹果,用 cat
zhao.part* > zhao.mp3就可以
如果用的是Windows,用copy
/b 来解决吧,呵呵
上面讲的都是http协议的下载,其实ftp也一样可以用。
用法嘛,
curl -u name:passwd
ftp://ip:port/path/file
或者大家熟悉的
curl
ftp://name:passwd@ip:port/path/file
10)上传的option是
-T
比如我们向ftp传一个文件: curl
-T localfile -u name:passwd
ftp://upload_site:port/path/
当然,向http服务器上传文件也可以
比如 curl -T localfile
http://cgi2.tky.3web.ne.jp/~zzh/abc.cgi
注意,这时候,使用的协议是HTTP的PUT
method
刚才说到PUT,嘿嘿,自然让老服想起来了其他几种methos还没讲呢!
GET和POST都不能忘哦。
http提交一个表单,比较常用的是POST模式和GET模式
GET模式什么option都不用,只需要把变量写在url里面就可以了
比如:
curl
http://www.yahoo.com/login.cgi?user=nickwolfe&password=12345
而POST模式的option则是 -d
比如,curl -d "user=nickwolfe&password=12345"
http://www.yahoo.com/login.cgi
就相当于向这个站点发出一次登陆申请~~~~~
到底该用GET模式还是POST模式,要看对面服务器的程序设定。
一点需要注意的是,POST模式下的文件上的文件上传,比如
<form
method="POST" enctype="multipar/form-data"
action="http://cgi2.tky.3web.ne.jp/~zzh/up_file.cgi">
<input type=file
name=upload>
<input type=submit name=nick
value="go">
</form>
这样一个HTTP表单,我们要用curl进行模拟,就该是这样的语法:
curl -F
upload=@localfile -F nick=go
http://cgi2.tky.3web.ne.jp/~zzh/up_file.cgi
罗罗嗦嗦讲了这么多,其实curl还有很多很多技巧和用法
比如
https的时候使用本地证书,就可以这样
curl -E
localcert.pem
https://remote_server
再比如,你还可以用curl通过dict协议去查字典~~~~~
curl
dict://dict.org/d:computer
今天为了检查所有刺猬主机上所有域名是否有备案.在使用wget不爽的情况下,找到了curl这个命令行流量器命令.发现其对post的调用还是蛮好的.特别有利于对提交信息及变
更参数进行较验.对于我想将几十万域名到miibeian.gov.cn进行验证是否有备案信息非常有用.发现这篇文章很不错,特为转贴.
我的目标:
curl -d
"cxfs=1&ym=xieyy.cn"
http://www.miibeian.gov.cn/baxx_cx_servlet
在出来的信息中进行过滤,提取备案号信息,并设置一个标识位.将域名,备案号及标识位入库
用curl命令,post提交带空格的数据
今天偶然遇到一个情况,我想用curl登入一个网页,无意间发现要post的数据里带空格。比如用户名为"abcdef",密码为"abc
def",其中有一个空格,按照我以前的方式提交:
curl -D cookie -d
"username=abcdef&password=abc def"
http://login.xxx.com/提示登入失败。
于是查看curl手册man
curl。找到:
d/--data (HTTP)
Sends the speci?ed data in a POST request to the HTTP server, in a
way that can emulate as if a user has ?lled in a HTML form and
pressed the
submit button. Note
that the data is sent exactly as speci?ed with no extra processing
(with all newlines cut off). The data is expected to be
"url-encoded".
This will cause curl
to pass the data to the server using the content-type
application/x-www-form-urlencoded. Compare to -F/--form. If this
option is used
more than once on
the same command line, the data pieces speci?ed will be merged
together with a separating &-letter. Thus, using
’-d name=daniel -d
skill=lousy’ would
generate a post chunk that looks like
’name=daniel&skill=lousy’.
于是改用:
curl -D cookie -d
"username=abcdef" -d "password=abc efg"
http://login.xxx.com/这样就能成功登入了。
Curl是Linux下一个很强大的http命令行工具,其功能十分强大。
1) 二话不说,先从这里开始吧!
$ curl http://www.linuxidc.com
回车之后,www.linuxidc.com
的html就稀里哗啦地显示在屏幕上了
2) 嗯,要想把读过来页面存下来,是不是要这样呢?
$ curl http://www.linuxidc.com > page.html
当然可以,但不用这么麻烦的!
用curl的内置option就好,存下http的结果,用这个option: -o
$ curl -o page.html http://www.linuxidc.com
这样,你就可以看到屏幕上出现一个下载页面进度指示。等进展到100%,自然就 OK咯
3) 什么什么?!访问不到?肯定是你的proxy没有设定了。
使用curl的时候,用这个option可以指定http访问所使用的proxy服务器及其端口: -x
$ curl -x 123.45.67.89:1080 -o page.html http://www.linuxidc.com
4) 访问有些网站的时候比较讨厌,他使用cookie来记录session信息。
像IE/NN这样的浏览器,当然可以轻易处理cookie信息,但我们的curl呢?.....
我们来学习这个option: -D <— 这个是把http的response里面的cookie信息存到一个特别的文件中去
$ curl -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,当页面被存到page.html的同时,cookie信息也被存到了cookie0001.txt里面了
5)那么,下一次访问的时候,如何继续使用上次留下的cookie信息呢?要知道,很多网站都是靠监视你的cookie信息,来判断你是不是不按规矩访问他们的网站的。
这次我们使用这个option来把上次的cookie信息追加到http request里面去: -b
$ curl -x 123.45.67.89:1080 -o page1.html -D cookie0002.txt -b cookie0001.txt http://www.linuxidc.com
这样,我们就可以几乎模拟所有的IE操作,去访问网页了!
6)稍微等等
对了!是浏览器信息
有些讨厌的网站总要我们使用某些特定的浏览器去访问他们,有时候更过分的是,还要使用某些特定的版本
好在curl给我们提供了一个有用的option,可以让我们随意指定自己这次访问所宣称的自己的浏览器信息: -A
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,服务器端接到访问的要求,会认为你是一个运行在Windows 2000上的 IE6.0,嘿嘿嘿,其实也许你用的是苹果机呢!
而"Mozilla/4.73 [en] (X11; U; Linux 2.2; 15 i686"则可以告诉对方你是一台 PC上跑着的Linux,用的是Netscape 4.73,呵呵呵
7)另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的
referer地址就是第一次访问成功后的页面地址。这样,服务器端只要发现对下载页面某次访问的referer地址不是首页的地址,就可以断定那是个盗
连了
讨厌讨厌
~我就是要盗连
幸好curl给我们提供了设定referer的option: -e
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e "mail.linuxidc.com" -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,就可以骗对方的服务器,你是从mail.linuxidc.com点击某个链接过来的了,呵呵呵
8)写着写着发现漏掉什么重要的东西了!——- 利用curl 下载文件
刚才讲过了,下载页面到一个文件里,可以使用 -o ,下载文件也是一样。比如,
$ curl -o 1.jpg http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这里教大家一个新的option: -O 大写的O,这么用:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这样,就可以按照服务器上的文件名,自动存在本地了!
再来一个更好用的。
如果screen1.JPG以外还有screen2.JPG、screen3.JPG、....、screen10.JPG需要下载,难不成还要让我们写一个script来完成这些操作?
不干!
在curl里面,这么写就可以了:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen[1-10].JPG
呵呵呵,厉害吧?! ~
9)再来,我们继续讲解下载!
$ curl -O http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
这样产生的下载,就是
~zzh/001.JPG
~zzh/002.JPG
...
~zzh/201.JPG
~nick/001.JPG
~nick/002.JPG
...
~nick/201.JPG
够方便的了吧?哈哈哈
咦?高兴得太早了。
由于zzh/nick下的文件名都是001,002...,201,下载下来的文件重名,后面的把前面的文件都给覆盖掉了 ~
没关系,我们还有更狠的!
$ curl -o #2_#1.jpg http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
—这是.....自定义文件名的下载? —对头,呵呵!
这样,自定义出来下载下来的文件名,就变成了这样:原来: ~zzh/001.JPG —-> 下载后: 001-zzh.JPG 原来: ~nick/001.JPG —-> 下载后: 001-nick.JPG
这样一来,就不怕文件重名啦,呵呵
2014圣诞祝福-可以自定义好友名字的祝福-个性十足 资源分享


PHP性能优化 代码人生
一、规范说明
性能是网站运行是否良好的关键因素, 网站的性能与效率影响着公司的运营成本及长远发展,编写出高质高效的代码是我们每个开发人员必备的素质,也是我们良好的职业素养。
二、影响性能的因素
A、 商业需求
1. 需求合理性
2. 需求与系统的整合
3. 需求所带来的商业利益是否与需求开发的成本成正比
4. 需求所带来的风险
B、 Web 服务器
1. 并发处理能力
2. 高负载的能力
3. 负载均衡的能力
4. 动态内容与静态内容的处理能力
5. Web 服务器部署
C、 DataBase 服务器
1. 并发访问
2. 数据库服务器的部署
3. 数据库的 shema 架构与的表设计是否合理
4. 数据检索
D、 操作系统
E、 客户端请求
F、 程序/语言
三、分析性能的指标
1. 程序的运行时间 2
2. 程序的运行所消耗的内存
3. 单位时间内的并行处理
4. 磁盘 IO 的处理
四、优化性能的目标
快速、并发、资源消耗低(内存、磁盘 IO、CPU 负载)
五、优化性能的原则
1. 服务器配配置最优化
2. 服务器部署合理化
3. 商业需求合理并与产出的商业价值成正比
4. 架构可用、可维护、可扩展
5. 程序的正确性、简单性、逻辑的合理性。
6. 不断的分析性能的的瓶颈
7. 不断的重构已有的代码
8. 优化的优先级:program->database->web sersver->os->client
六、优化
A、 程序优化
· 变量
1、 变量大小,注意变量大小是节约内存的最有效手段,对于来自用户表单、数据库和文件缓存的数据都需要控制变量的大小。 因为cpu要处理的数据是来源于内存
2、 变量有效期,使用unset()函数注销不需要的变量是一种良好的习惯,将一些不需要的变量立即注销可提高内存的使用率。
3、 复制变量,尽量不要复制变量,否则就会带来1倍的内存消耗,即使复制变量也应该要立即注销原有变量。
4、 变量类型,初始化变量请注意其变量类型,一个变量在执行过程中最好只有一种类型状态。对于数组变量,请初始化声明,如下: $a = array();
5、 临时变量,是处理业务逻辑的临时存储,这些都是需要消耗内存的。如果临时变量使用结束请立即注销,特别是在一些过程式代码的执行流程中,对于一些函数,如果业务非常复杂,同样需要立即注销临时变量
6、 静态变量,对于一些需要由复杂业务产生的变量,如果在程序的执行过程中多次产生并使用,可考虑使用静态变量,减少程序的cpu执行次数
7、 变量的性能:局部变量>全局变量>类属性>未定义的变量。
· 循环
1、 尽量减少循环的次数。
2、 尽量减少循环的潜逃的层次,不要超过三层。
3、 避免在循环内有过多的业务逻辑。
4、 不要循环包含文件
5、 不要循环执行数据库操作。
6、 优先使用foreach,它比for/while效率高
7、 不要把 count/strlen/sizeof 放到 for 循环的条件语句中 For($i=0,$count=count($array);$i<$count;$i++){} 不要使用for($i=0;$i<count($array);$i++){};
8、 for($i=$total;$i>0;$i–){}性能好于for($i=0;$i<$total;$–){}
9、 保持循环体内的业务逻辑清晰
· 函数
1、 函数职责清晰,一个函数只干一件事,不要杂揉过多的业务逻辑
2、 函数代码体不要超过20行,反之,考虑拆分。
3、 优先使用php内置函数
4、 常量与函数同时能干一件事,优先使用常量。
· phpversion() < PHP_VERSION
· get_class() < CLASS
· is_null() < NULL ===
5、 echo 的性能好于print,输入多个变量的时候用echo $str,$str1,不用.连接符
6、 $_SERVER[REQUEST_TIME]替换time();
7、 字符串替换strtr()->str_replace()->preg_replace()->epreg();
8、 发挥trim最大功效,替换substr。$filepath=trim($filename,’/’).’/’;
9、Isset/empty 虽然两个函数功能有所差异,但在同样的情况下推荐使用 empty()
10、isfile/file_exist 两个函数的功能有所不同,file_exist既可判断文件是否存在,也可以判断目录是否存在,在同样的情况下推荐使用is_file
· 文件
1、 减少文件包含数,减少磁盘 IO
2、 使用完整路径,或者容易转换的相对路径。避免在 include_path 查找
3、 文件的代码行数不要超过 2000 行
4、Require_once/include_once 效率低于 require/include, 需要额外的去查看系统是否已经调用过这个文件. 因为它们在一个 opcode 缓存下的调用非常慢
5、程序执行文件用 requie/require_once,缓存文件用include/include_once。Include 效率好于 require
6、优化 spl 中的文件自动加载机制,可参靠 yii
7、类库文件加载,是否考虑类是否已经实例化,可考虑采用设计模式之单例模式
8、文件读写的并发性
面向对象
1、 控制实例的创建的数量
2、 优先使用常量、类常量
3、 优先例用静态变量,静态属性
4、 类的结构合理
5、 面象接口编程
6、 封装变化点
7、 依赖于抽象,不依赖于细节
8、 优先使用静态成员
9、 类的接口清晰稳定,类的职责单一,类与类的通信合理
10、 使用常量的好处 编译时解析,没有额外开销 杂凑表更小,所以内部查找更快 类常量仅存在于特定「命名空间」,所以杂凑名更短 代码更干净,使除错更方便
字符串
1、 用单引号替代双引号引用字符串;避免检索字符串中的变量
运算
1、 用 i+=1 代替i=i+1。符合c/c++的习惯,效率还高
2、 ++$i 的效率高于++$i,–$i 同理
数组
1、 多维数组尽量不要循环嵌套赋值;
2、 使用$array[‘name’]方式访问数组,禁止$array[name]/$array[“name”]
判断
1、 逻辑判断请优先使用switch 的方式,对于业务逻辑相对较多的情况请选择if/else,提高代码的可读性
2、 尽量控制if/else判断的个数,如果太多请考虑功能优化或代码优化
3、 尽量使用恒等用于比较判断,恒等的效率高于等于,而且还能避免一些类型强制转换的错误
4、 if/else与_&&,单条语句判断请选择&&的形式, &&的效率高于if/else,如下 :
if ($a == 1) {
$b = 2;
}可选择为($a == 1) && $b = 2;
缓存
1、 使用php加速器,缓冲opcode
2、 例用memcache/nosql
3、 使用内存数据库、
4、 使用文件缓存
5、 缓冲功能 5
其它
1、 少用@符号,严重影响性能
2、 适时关闭远程资源连接如数据库,ftp、socket等,适时的清理这些资源
B、 数据库优化
1、 合理的商业需情
2、 数据库 schema 架构优化
3、 垂直与水平分库分表
4、 索引优化,查询优化
5、 第三方开源检索工具(sphinx)
6、 主从数据库服务器的使用。
C、 Web 服器优化(暂未整理,有相应的 Web 服务器优化手册)
D、 操作系统优化(暂未整理,有相应的 OS 优化手册)
E、 前端优化
1、合理的 html 结构
2、合理 html 与css 的同时,考虑 Css 设计合理,减少 http 请求
3、合理 html 与java script 的同时,考虑拆分是否合理,减少 http 请求
4、优化 java script 代码,让用户有良好的体验
5、根据 http 协议,优化高并发请求
七、性能检测工具
Web Server
ab
http_load
PHP
apd
xdebug
Mysql
explain
profiler
-
admin 约 4 小时前
@rookie:没做
-
@无敌:无
-
www.rxka.com/ 请问又这个网站的密码吗
-
求教一下 118.195.198.108:20001/
-
@人大代表:我不知道 也不评论
-
@admin:坦白从宽,你懂的。
-
admin 2024-03-28 22:38
@人大代表:卧槽 别搞我...
-
24年的新闻,你22年爆出来了。厉害了,大哥。
-
@wenjie:抱歉,不方便.
-
wenjie 2024-03-26 23:58
您好,我是一名记者。您2022年12月一篇博文中提到的武汉晓...


